

Trong bài viết Bàn về Monolith, Microservices, và Event-Driven Microservices chúng ta đã nói về xu thế hiện nay trong thiết kế hệ thống. Có thể bạn sẽ thấy phân vân về Event-Driven Microservices. Ngắn gọn thì: Event-Driven Microservices = Microservices + Event-Driven.
Bài viết này, chúng ta sẽ tìm hiểu sơ bộ về kiến trúc này. Các bài viết chuyên sâu từng khía cạnh, từng patterns sẽ có sau.
Các từ "service" và "microservice" trong bài này mình dùng với chung mục đích là chỉ các dịch vụ trong hệ thống Microservices.
Sơ lược về Event-Driven Microservices
Mục đích chủ yếu của Microservice là gì? Đó là:
- Phân chia hệ thống thành những dịch vụ (service) nhỏ hơn sao cho mỗi service nằm trong (hay phụ trách) một bounded context xác định. Ở đây, bounded context là một phần nghiệp vụ bao gồm các use case có tính gắn kết (cohesion) cao, không thể tách rời.
- Việc phân chia này mang lại nhiều lợi thế như hiệu năng hệ thống nói chung tốt hơn, nhất là ở những hệ thống lớn; tính phát triển, triển khai độc lập giữa các service; phân chia nguồn lực đội nhóm phát triển được tối ưu hơn; công nghệ của mỗi service cũng có thể khác nhau.
- Tuy vậy, nó cũng có những thách thức lớn hơn so với Monolith ở khía cạnh phức tạp hệ thống, cần nhiều nguồn lực, công nghệ giám sát hơn, việc kiểm thử cũng phức tạp hơn,...
Với kiến trúc Microservices truyền thống, giao tiếp giữa các service chủ yếu sử dụng cơ chế synchronous qua API. Mặc dù việc phân chia ứng dụng lớn thành các vi-dịch-vụ đã mang lại nhiều lợi thế trong phát triển và vận hành hệ thống nhưng do vấn đề của synchronous API, nếu ta không bảo trì kiến trúc một cách khéo léo, cả hệ thống có thể trở thành một distributed monolith. Trong distributed monolith, vấn đề "big ball of mud" (mớ bòng bong) thậm chí còn nâng lên ở cấp độ cao hơn, phức tạp hơn nhiều do sự đan xen giữa các service tách biệt. Ngoài ra, synchronous API còn có thể gây ra vấn đề hiệu năng khi các service phụ thuộc, móc nối với nhau thành một chuỗi dài để giải quyết một nghiệp vụ.
Event-driven, mặt khác, lại mang tới nhiều lợi thế (bên cạnh một vài bất lợi mà ta sẽ bàn tới trong các chủ đề cụ thể) cho hệ thống Microservices, một trong số đó là khả năng giao tiếp bất đồng bộ (asynchronous) thông qua cơ chế messaging, giúp cho các service thành phần nâng cao sự tự chủ cũng như giúp hệ thống có thể mở rộng mà không ảnh hưởng tới những dịch vụ vốn có,...
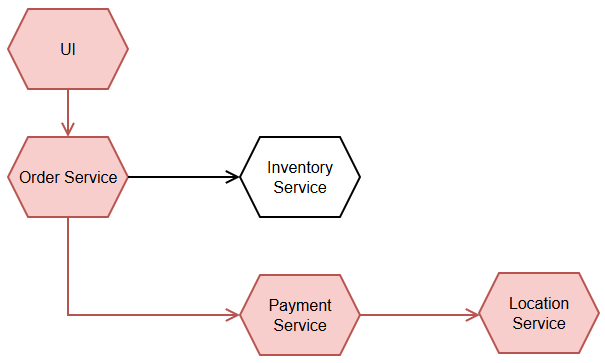
Hình 1 thể hiện sự lan truyền lỗi giữa các service trong kiến trúc Microservices sử dụng các lời gọi synchronous API. Ứng dụng cuối UI được người dùng thao tác đặt hàng, lời gọi được gửi đến Order Service. Order Service gọi hai service tiếp theo là Inventory Service để cập nhật tồn kho, và Payment Service để tính phí. Trong quá trình tính phí, Payment Service gọi tới Location Service để đo đạc khoảng cách lấy-giao của đơn hàng. Giả sử, Location Service bị lỗi do quá tải, lỗi được lan truyền ngược lại theo thứ tự Payment Service sang Order Service và cuối cùng tới UI.
Hãy tưởng tượng, trong một hệ thống với hàng chục cho tới hàng trăm dịch vụ, mức độ phụ thuộc của từng dịch vụ trong đó rắc rối hơn hình 1 rất nhiều. Nguy cơ lỗi lan truyền như vậy là một rủi ro lớn của hệ thống. Chính vì thế, người ta gọi là "distributed monolith". (Microservices có một pattern để làm dịu đi vấn đề này, đó là Circuit Breaker Pattern, sẽ có bài riêng về pattern này)
Bây giờ, giả sử ta đặt thêm vào đó một message queue.
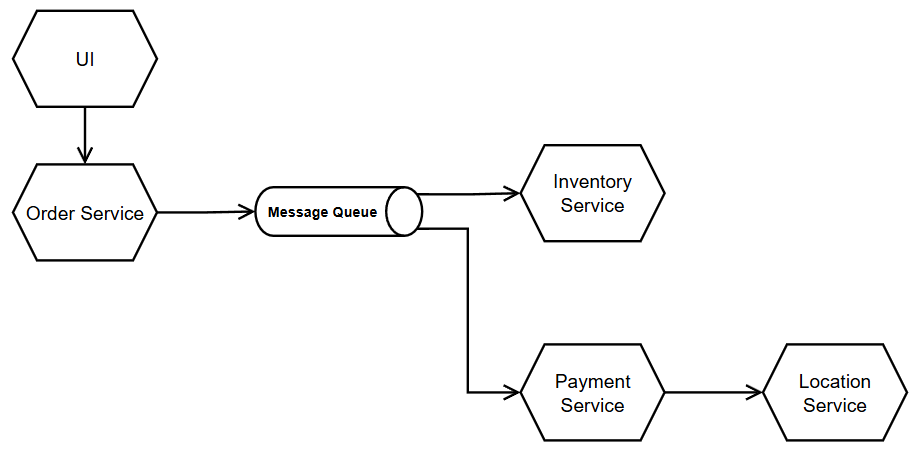
Một message queue đã được đặt đằng sau một Order Service giúp nó giao tiếp với Inventory Service và Payment Service bằng cơ chế bất đồng bộ asynchronous. Cụ thể hơn,
- Khi Order Service tiếp nhận yêu cầu từ UI, nó thực hiện tạo ra một order mới. Ngay lập tức, nó thông báo với các dịch vụ khác (đã đăng ký với nó) rằng "có một order vừa được tạo ra".
- Các dịch vụ khác đã đăng ký lắng nghe sẽ biết được thông tin này, thực hiện lấy về thông tin đó và làm công việc của mình. Inventory cập nhật tồn kho, Payment Service thanh toán.
- Giả sử, Location Service gặp lỗi, sẽ chỉ Payment Service bị ảnh hưởng do giao tiếp vẫn là API. Điều này đạt được do ta đã chuyển cơ chế giao tiếp API sang messaging ở một số bước. Tất nhiên, thiết kế trải nghiệm người dùng sẽ cần thay đổi đôi chút (sau này bạn sẽ thấy, không phải tình huống nào cũng đặt được vào giao tiếp asynchronous, nội dung này sẽ bàn tới sau).
Hình 2 cũng cho thấy một điều: Khi triển khai một kiến trúc Event-Driven Microservices, ta không nên thiết lập toàn bộ các giao tiếp qua cơ chế messaging. Bởi điều này đôi khi không hợp lý trong trải nghiệm người dùng ở một số use case cũng như gây phức tạp hệ thống hơn mức cần thiết. Nhưng may mắn thay, nếu nơi nào trong hệ thống của bạn cần cơ chế này, thì khả năng cao bạn có thể triển khai được.
Message Queue trong hình 2 không nên share chung để toàn bộ các service đều có thể push thông tin lên khi mà chúng không làm cùng một nghiệp vụ, hay chúng có tính cohesion thấp. Ở đây, tôi đề cập tới việc có thể có nhiều service cùng push lên đó event, nhưng chúng nên có tính cohesion cao. Thực tế tôi thường gặp là mỗi service ít nhất một message queue input để tiếp nhận thông tin đầu vào (command) và một message queue output để phát ra sự kiện đã xảy ra trong nó (event). Mỗi message queue nên chứa các thông tin về một nghiệp vụ nào đó.
Message queue output như vậy gọi là Source of Truth (nguồn sự thật): Nếu bất cứ service nào cần thông tin liên quan tới đơn hàng, hãy lấy từ đó vì đó là nơi duy nhất trong toàn bộ hệ thống chứa thông tin đó.
Cùng xem một service topology điển hình:
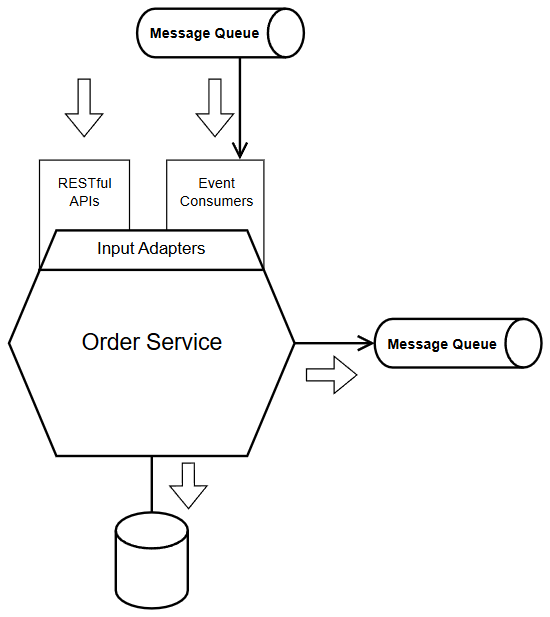
Hình 3 thể hiện một cấu trúc cơ bản của một service trong kiến trúc Event-Driven Microservices:
- Input Adapters là một khái niệm trong Hexagonal Architecture, ở đó quy định các giao tiếp với thế giới bên ngoài, ở đây là thông qua RESTful APIs, và Event Consumers.
- RESTful APIs đảm bảo rằng service có thể cung cấp cơ chế giao tiếp đồng bộ cho những use case cần trả về kết quả ngay. Còn Event Consumers pull events từ một Input Queue, gọi tới use case.
- Message queue giúp service triển khai Event-Driven, chia sẻ dữ liệu với các dịch vụ khác cần tới nó. (Hãy nhớ rằng, các queue như vậy đảm bảo cả việc chia sẻ dữ liệu nhé.)
- Như vậy, bạn có thể thấy, có thể có những tình huống mà cùng một nghiệp vụ (use case) mà bạn có thể có hai Input Adapters khác nhau: RESTful hoặc qua Event Consummers. Bạn đã bao giờ gặp tình huống như vậy chưa? Thậm chí, tôi còn gặp tình huống phải triển khai các batch job trên các service này, khi đó nó đóng vai trò một Input Adapter nữa, và nó gọi use case trong ứng dụng.
- Sau khi tiếp nhận yêu cầu, command, service thực thi nghiệp vụ tương ứng và kết quả sau đó là một thông báo ra bên ngoài rằng có một sự kiện nào đó đã xảy ra trong bản thân nó. Hành động này được thực hiện bằng cách service publish một sự kiện vào message queue đầu ra. Phần sau chúng ta sẽ đề cập tới các loại message mà một service có thể tạo ra và thông báo.
Cụ thể hơn về một lợi thế của kiến trúc Event-Driven mà tôi đã đề cập: tính mở rộng theo chiều ngang của hệ thống.
Để ý trong hình 3, giả sử nó tương ứng với message queue để Order Service thông báo về việc quản lý đơn hàng của nó. Kết quả là trong queue này sẽ có những event liên quan tới việc tạo mới cũng như cập nhật đơn hàng như OrderCreatedEvent, OrderAddressChangedEvent, OrderItemsUpdatedEvent,... Hiện tại đang có hai service là Inventory Service và Payment Service lắng nghe các sự kiện này và có hành động xử lý riêng cho nghiệp vụ của chúng. Nếu lúc này, ta phát sinh thêm yêu cầu truy vấn thống kê tình hình kinh doanh như các sales report thì sao? Thay vì truy vấn dữ liệu rời rạc từ các service thành phần rồi tổng hợp dữ liệu lại ở một điểm trung tâm (có thể bạn đã biết, đó là API Composition Pattern) gây tiềm ẩn về hiệu năng và phức tạp thì ta có thể tạo thêm một service đảm nhận các nhiệm vụ dạng tổng hợp dữ liệu như vậy, bằng cách cho nó lắng nghe các sự kiện liên quan, trong đó có message queue này. Việc bổ sung thêm nghiệp vụ, và do đó là cả một service mới không hề ảnh hưởng tới Order Service hay bất cứ service nào hiện có trong hệ thống.
Theo cá nhân tôi nhận thấy, thách thức lớn nhất trong kiến trúc Event-Driven Microservices này là việc xác định ranh giới giữa các service.
Ranh giới
Nếu bạn đã biết về nguyên lý CCP, bạn sẽ thấy mục tiêu của nó thế này: Nếu có thay đổi trong hệ thống, ta mong muốn mọi thay đổi đó tập trung ở một số nhỏ các thành phần thay vì trải rộng khắp hệ thống. Bởi điều này giúp giảm đi sự phụ thuộc lẫn nhau giữa các team (do đó, phát sinh chi phí thời gian, công sức để trao đổi), giảm đi số lượng đơn vị phần mềm cần tái triển khai, và giảm đi sự phụ thuộc triển khai giữa các đơn vị đó (rõ ràng khi có nhiều microservices phụ thuộc nhau qua API thì bạn cần một thứ tự triển khai chính xác giữa chúng).
Vậy CCP liên quan gì tới nội dung mà ta đề cập ở đây? Nó giúp ta có một ranh giới tốt hơn giữa các service và qua đó có kế hoạch triển khai loại kiến trúc này hiệu quả hơn.
Trong một thế giới lý tưởng, bạn có các microservices tối ưu, trong đó mỗi microservice đảm nhận đúng vai trò của nó với một bounded context nằm chính xác trong từng subdomain của tổ chức. Thực tế thì có khá nhiều thống kê cho thấy điều ngược lại. Thế giới thực thường lộn xộn hơn, cho nên ta mới hay mơ tới thế giới lý tưởng. Do đó, việc xác định đúng các microservices là điều quan trọng, và bạn có thể có hai hướng chính:
Áp dụng nguyên lý CCP
Nếu trong trường hợp bạn phân rã service quá sớm (thật đáng buồn là điều này hay xảy ra do giờ đây ai cũng nghĩ về Microservices), và bạn thường xuyên phải re-deploy quá nhiều service ở mỗi lần cập nhật, bạn cần xem xét việc gom những service hay đi cùng nhau lại với nhau. Tất nhiên, chi phí tái tổ chức ranh giới vật lý (hợp nhất các service) là lớn nhưng có lẽ đó là việc đáng để làm. Kết quả là hệ thống của bạn sẽ có ít service hơn, có những service to hơn số còn lại. Nên tạo thói quen tổ chức module nghiệp vụ trong từng service dù chúng to hay nhỏ nhé!
Áp dụng Domain Driven Design (DDD)
Một cách tiếp cận hướng nghiệp vụ hơn khi xác định ranh giới: Sử dụng kiến thức về miền nghiệp vụ (domain knowledge) qua các buổi trao đổi với chuyên gia miền (domain expert) bằng cách tổ chức các buổi Event Storming. Tại buổi đó, mọi người có quyền nói về nghiệp vụ, bằng ngôn ngữ nghiệp vụ (Ubiquitous Language). Với bảng trắng và các sticky note cùng các cái ghim, bạn cùng mọi người xác định những sự kiện chính của hệ thống. Trong số các sự kiện đó, bạn định nghĩa các thông tin tương ứng một cách sơ bộ, rồi xác định xem, giữa một chuỗi sự kiện đó, những cái nào có sự thay đổi đáng kể về trạng thái dữ liệu. Đó là một thông tin để bạn xác định bounded context, và do đó là microservice.
Tất nhiên, kỹ thuật này áp dụng vào thực tế cần thời gian kiểm chứng sự hiệu quả và bạn nên kết hợp thật nhiều kiến thức domain trong đó nữa.
Một kỹ thuật nữa người ta hay dùng là theo định luật Conway: "Bất kỳ tổ chức nào thiết kế một hệ thống sẽ không thể tránh khỏi việc tạo ra một thiết kế có cấu trúc giống với cấu trúc giao tiếp của tổ chức đó." Vậy bạn có thể xác định ranh giới "xuôi" theo cấu trúc giao tiếp giữa các team hiện có. Hoặc, nếu bạn đủ cứng rắn: ép các team với cấu trúc giao tiếp hiện tại tái cơ cấu theo kiến trúc mà bạn đưa ra!
Bạn nên áp dụng các phương pháp khác nhau để đạt được ranh giới phù hợp nhất.
Dù thế nào, hãy luôn nhớ rằng, ranh giới đó không tĩnh mà sẽ thay đổi theo thời gian:
- Có thể do ranh giới ban đầu chưa phù hợp và do đó nó cần điều chỉnh lại cho phù hợp hơn.
- Hoặc, ngay cả ranh giới đó là phù hợp nhưng dòng chảy của kinh doanh luôn biến động, và chúng ta, những kỹ sư phần mềm phải điều chỉnh phần mềm cho phù hợp với tình hình của tổ chức.
Có một số tình huống mà ta có thể phân ranh giới theo công thức được. Dưới đây là các tình huống đó.
Đáp ứng tiêu chuẩn về dữ liệu
Một số dịch vụ phải xử lý dữ liệu nhạy cảm như PII (thông tin nhận dạng cá nhân), PCI DSS (tiêu chuẩn bảo mật dữ liệu ngành thẻ thanh toán), hoặc PHI (thông tin sức khỏe được bảo vệ). Khi đó, ta phải bổ sung thêm các quy định cũng như đáp ứng được yêu cầu kiểm toán từ bên thứ ba. Nếu triển khai vào một service thông thường sẽ thường tốn nhiều công sức. Ví dụ, để dáp ứng "quyền được quên" trong GDPR, ta thường phải đảm bảo xóa mọi dữ liệu liên quan đến người dùng khi người đó không còn sử dụng dịch vụ nữa. Việc tìm và xóa cơ bản đã phức tạp, còn khó hơn với hệ thống sử dụng events. Cách làm thông thường mà sử dụng mã hóa dữ liệu. Khi tình huống cần phải xóa, thay vì ta xóa dữ liệu thì ta xóa khóa giải mã dữ liệu của người dùng. Lúc này dữ liệu sẽ không được giải mã nữa. Cụ thể về cách thức này sẽ bàn ở bài viết khác.
Những chức năng cần đáp ứng vấn đề này ta có thể gom chúng vào một hoặc một vài service đặc thù, được thiết kế cho những mục đích như vậy.
(Phần tiếp theo sẽ bàn về các loại message trong kiến trúc Event-Driven Microservices)