

Series bài viết về Hexagonal:
- Bài 1: Xem lại Layered Architecture.
- Bài 2: Bài này, từng bước chuyển đổi một Layered Architecture sang Hexagonal Architecture
- Bài 3: Tiếp tục chuyển đổi và bàn về quá trình tạo mới cùng cơ chế Validate Domain Entity.
- Bài 4: Hoàn thiện quá trình chuyển đổi Layered Architecture sang Hexagonal Architecture.
Phần trước, chúng ta đã đi qua cách triển khai ứng dụng theo kiến trúc Layered truyền thống. Bên cạnh một số ưu điểm thì những nhược điểm của nó nổi trội hơn. Layered Architecture còn khiến cho chúng ta xây dựng ứng dụng theo hướng từ dưới lên: Đầu tiên là thiết kế database, sau đó tới các entity đại diện cho các bảng, các repository giúp thao tác với database, và cuối cùng tới lớp nghiệp vụ.
Phần 2: Giới thiệu và chuyển đổi Layered sang Hexagonal
Logic nghiệp vụ là trái tim của ứng dụng và là nơi được ta đầu tư nhiều thời gian nhất để chăm lo trong vòng đời của nó. Thay vì đi theo hướng phát triển Layered truyền thống, người ta đi theo hướng lấy chính logic nghiệp vụ làm trung tâm, như vai trò vốn có của nó. Nếu như ở mô hình Layered, Service Layer là nơi chứa nghiệp vụ của ứng dụng, lại đi phụ thuộc vào Data Access Layer (cũng như cả framework) thì để đưa nó về trung tâm theo ý tưởng trên, bạn biết làm gì rồi phải không? Ta cần “đảo ngược phụ thuộc - DIP”: Đưa Data Access Layer phụ thuộc ngược lại vào Service Layer:
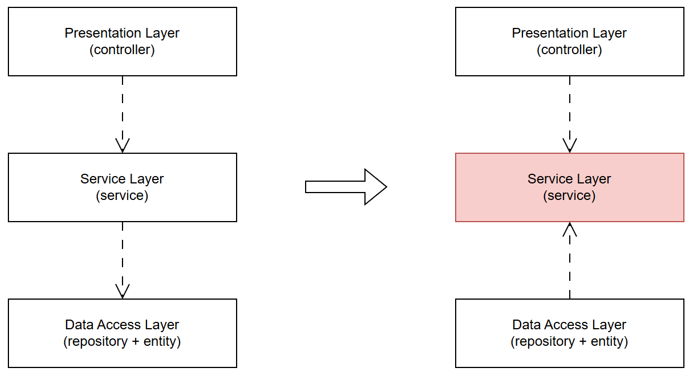
Tại sao lại cần đưa nó về trung tâm, điều này mang lại lợi ích gì?
Nếu Service Layer phụ thuộc vào Data Access Layer, nó có thêm một lý do để thay đổi ngoài những lý do của chính bản thân nó thì giờ đây, nó trở thành trung tâm, tất cả phụ thuộc vào nó. Từ đó, Service Layer có thể phát triển để mô phỏng đúng nghiệp vụ nó phụ trách mà không bị ảnh hưởng bởi những yếu tố khác như công nghệ (như framework), và bên ngoài (như database).
Đó là mục tiêu tốt nhưng cần thực hiện. Làm thế nào để đảo ngược phụ thuộc để đưa Service Layer vào trung tâm?
Đây là lúc sử dụng DIP ở các bài trước (DIP 1 và DIP 2). Ta cùng áp dụng nguyên lý này để đạt được ý tưởng thiết kế.
Chuyển đổi
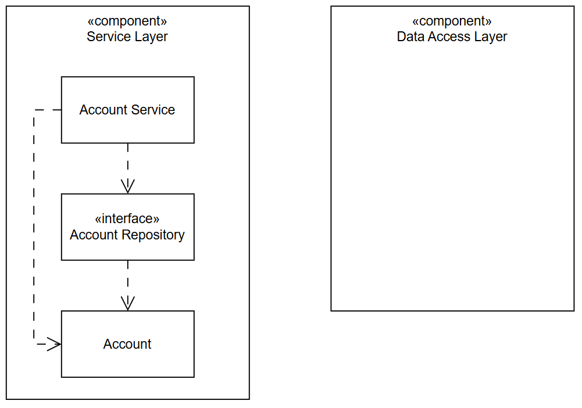
Quay lại hiện trạng với các lớp, các thành phần phụ thuộc nhau theo bức tranh sau:
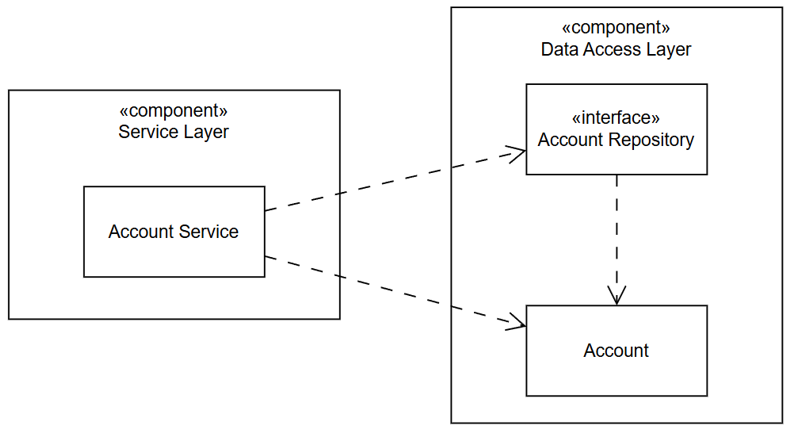
Làm thế nào để Data Access Layer phụ thuộc ngược lại Service Layer và Service Layer không còn phụ thuộc vào Data Access Layer?
Một cách rất đơn giản, trước hết, cần di chuyển AccountRepository sang phía Service Layer.
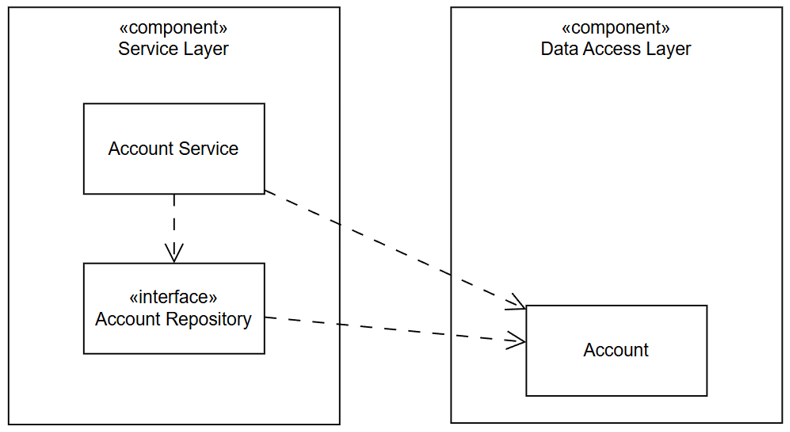
Đừng thất vọng khi bạn vẫn thấy hai mũi tên phụ thuộc trỏ từ Service Layer sang Data Access Layer, thậm chí AccountRepository lại nằm ở Service Layer, chẳng phải là đang phá vỡ ranh giới trách nhiệm của nó?
Tạm bỏ qua vị trí của AccountRepository để giải quyết hai mũi tên phụ thuộc giữa Service Layer và Data Access Layer trước. Nếu còn thiết kế Account là một data class thông thường, tức nó phản ánh database thì ta không thể làm gì được để đảo ngược phụ thuộc. Do đó, cần đưa Account về thiết kế domain entity. Điều này rất quan trọng, nó thay đổi tư duy của bạn nếu bạn đang làm theo lối mòn Layered Architecture. Nếu bạn đã quen với DDD, điều này rất bình thường.
Giờ ta sẽ thiết kế Account entity dưới dạng POJO để đảm bảo nó không còn phụ thuộc vào framework, database, và nó sẽ phản ánh thuần túy nghiệp vụ. Từ đó, ta dễ dàng đưa nó sang vùng Service Layer được rồi, vì nó đã không còn phản ánh database.
Thiết kế Hexagonal cho rằng Account lúc này đã nằm ở vùng còn cao hơn Service Layer, đó là Domain Layer. Ta sẽ gom Account vào Domain Layer mới:
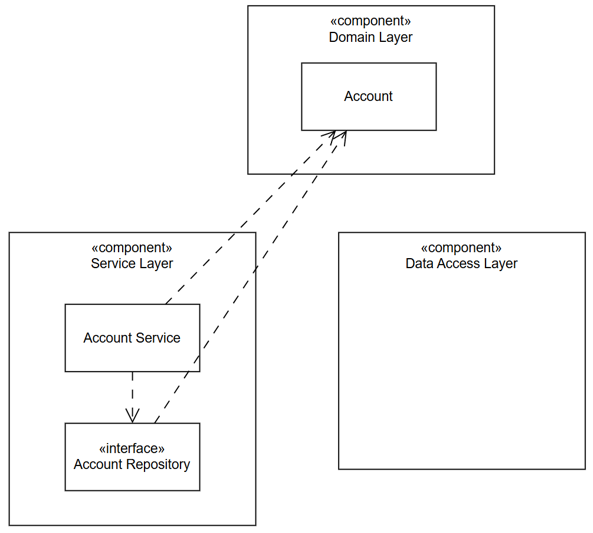
Account entity được đưa vào layer mới Domain LayerLợi ích của Account entity dưới dạng Domain Entity:
- Account trở thành class nghiệp vụ lõi chứ không thuần túy là data class nữa. Nó mang dữ liệu nghiệp vụ và hành vi nghiệp vụ lõi của domain.
- Team phụ trách phát triển nghiệp vụ ứng dụng chỉ cần quan tâm tới Account (hay rộng hơn là các Domain Entity), còn việc ánh xạ nó vào database họ sẽ không cần quan tâm. Mô hình ánh xạ có thể là một relational database, một document database, hay lưu dưới dạng file. Điều đó không quan trọng với team phát triển logic ứng dụng.
Ý thứ hai trong lợi ích mang lại cho ta một quy trình phát triển kiểu khác: Thay vì mô hình hóa database trước thì giờ ta tập trung vào business ứng dụng trước. Còn việc ánh xạ có thể trì hoãn sau, tại thời điểm quyết định xem cơ sở dữ liệu ta dùng là gì.
Tới đây, bạn sẽ có thể đặt ra các câu hỏi sau:
- AccountRepository tại sao vẫn nằm ở Service Layer?
- Data Access Layer rỗng không thì làm cách nào ứng dụng có thể truy cập database được?
Trả lời:
- Repository Pattern được sinh ra với phương pháp Domain-Driven Design (DDD), nó khác với Data Access Layer thuần túy, nó chỉ là một cách thức để domain nghiệp vụ lấy ra hay gửi đi các Domain Entity mà thôi. Còn nơi mà nó tương tác, database hay web service hay bất cứ nơi nào, nó không cần quan tâm. Do đó, Repository nằm ở nơi gần Domain hơn, cụ thể trong ví dụ này, nó gần Service Layer hơn là Data Access Layer. Data Access Layer sẽ là đóng vai trò thực hiện yêu cầu của Repository. (Cụ thể hơn về Repository Pattern, sẽ có ở bài khác.)
- Data Access Layer lúc này là các interface khác, giao tiếp với database như trong Layered Architecture. Để làm rõ, ta sẽ đi tiếp việc refactoring.
Tới lúc này, tầng Service Layer đã đạt được sự độc lập theo yêu cầu.
Cùng xem qua một chút code.
Đầu tiên là Account entity:
public class Account { private String email; private String name; private String password; public Account(String email, String name, String password) { this.email = email; this.name = name; this.password = password; }// ...Đối chiếu với Account entity trong Layered Archiecture, ta thấy class mới không có ID. Đây là lý do:
- Với nghiệp vụ này, tôi xác định email là key của thực thể Account. Nó phải đảm bảo tính unique trong toàn domain nghiệp vụ.
- Tôi có thể sử dụng ID như cũ nhưng cần bổ sung một UK (Unique Key) trong relational database triển khai bảng accounts tại cột email để đảm bảo tính đúng đắn của dữ liệu.
Với ý (2), bạn sẽ cho rằng trước khi insert, có thao tác kiểm tra sự tồn tại của email trong database là được. Thao tác này chưa đủ đảm bảo, vì có thể sau khi kiểm tra thấy không có và thực hiện insert dữ liệu, giữa hai thao tác đó, có một transaction đã insert thành công dữ liệu này. Do đó, dữ liệu bạn insert lúc này có cùng email nhưng ID đã tăng lên. Mặc dù, use case thêm mới account này khó xảy ra tính concurrency cao như vậy nhưng bạn có thể dùng nó cho các bài toán khác.
Do Account có email là ID, ta cần override hàm equals(), và do đó, cả hashCode():
@Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Account account = (Account) o; return Objects.equals(email, account.email); }
@Override public int hashCode() { return Objects.hashCode(email); }
Điều này là quan trọng vì nó đảm bảo tính unique của thực thể nghiệp vụ.
Còn hai thứ nữa ta cần giải quyết với lõi nghiệp vụ: Tăng tính module hóa để giúp cho nó có thể được sử dụng ở bất cứ nơi nào cần, và làm rõ cái gì thực thi giao tiếp với database qua AccountRepository. Hai thứ này dẫn ta đến hai khái niệm: Input Port và Output Port.
Input Port và Output Port
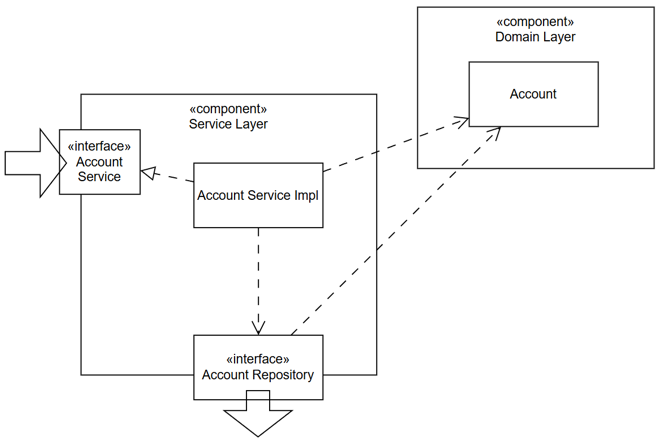
Do Service Layer giờ đây không còn phụ thuộc vào database, framework hay nói chung là bất cứ công nghệ cụ thể nào, nên nó có tính cơ động cao hơn trước. Ta có thể tái sử dụng nó. Để tính tính sử dụng một thành phần được nâng cao hơn nữa, thông thường người ta sẽ khai báo cho thành phần đó một số API – là các interface. Vậy ta sẽ biến AccountService thành interface và tạo ra một thực thi mặc định của nó là AccountServiceImpl.
Trong Hexagonal, AccountService interface đóng vai trò Input Port (hay Inbound Port), chìa ra chức năng của ứng dụng ra bên ngoài để được sử dụng. Còn AccountServiceImpl class là Use Case thực thi Input Port đó. Use Case rất quan trọng vì nó là nơi thực hiện nghiệp vụ bằng các thao tác điều phối: tiếp nhận đầu vào qua Input Port interface, sử dụng các Repository để lấy về các Domain Entity, tiếp tục đóng vai trò điều phối sự tương tác giữa các Domain Entity. Kết quả của sự tương tác sẽ được Use Case lưu lại, hoặc thông báo ra bên ngoài qua chính những Repository đó.
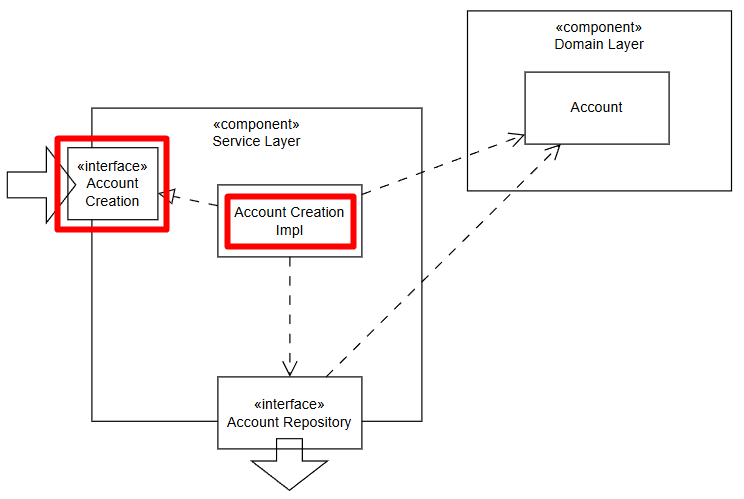
Giờ cùng nghĩ về cái tên phù hợp cho nghiệp vụ này. Nếu ta để AccountService, đồng nghĩa với việc sẽ có xu hướng các chức năng khác liên quan tới Account (các use case liên quan tới quản lý Account) cũng sẽ được đưa vào đây. Hexagonal không quy định rõ về điều này nhưng ta cần nâng cao chất lượng code của mình ở những nơi mà mình có thể. Nếu ta để những use case như vậy nằm trong AccountService, sau này có thể những use case đó phát triển với những tốc độ rất khác nhau, vì những lý do khác nhau (giảm tính cohesion). Hơn nữa, cái tên AccountService là khá chung chung. Ta sẽ đặt nó để thể hiện chức năng của tầng nghiệp vụ mà ta đang xây dựng: AccountCreation. Có thể sử dụng phiên bản khác là AccountCreationUseCase, nhưng tôi nghĩ để cái tên ngắn gọn cũng đủ mang lại ý nghĩa của nó rồi. Tương ứng với nó là use case: AccountCreationImpl.
Source code: Hexagonal Architecture Demo
(Do nội dung đã tương đối dài, nếu tiếp tục sẽ gây khó theo dõi nên tôi break tiếp ra phần 3.)