

Demo về Saga Orchestration ở đây.
Microservices Architecture là kiến trúc phần mềm thiên về định hướng triển khai khi mà các chức năng của hệ thống ứng dụng được phân chia ra những vi-dịch-vụ, microservices. Khi phân chia như vậy, mỗi microservice sẽ là một tiến trình riêng, chạy trên một tài nguyên riêng. Cách phân chia các chức năng ra các microservice khác nhau sẽ được bàn tới trong một bài viết khác. Ở đây, chúng ta bàn về cách chúng phối hợp với nhau để tạo nên một giao dịch toàn vẹn.
Mỗi microservice sẽ sở hữu riêng cho nó một hoặc nhiều database, tại đó, tính giao dịch ACID được đảm bảo mạnh mẽ. Nhưng có những use case cần phải trải dài qua nhiều microservice khác nhau, ví dụ, khi tạo một đơn hàng order thì
- Order-service phải kiểm tra số tồn kho và giảm số tồn kho của các sản phẩm tại Inventory-Service, sau đó
- Order này phải được thanh toán tại Payment-Service.
Nếu cả hai bước này thành công thì một order mới được tạo thành công, ngược lại, chỉ một trong số đó thất bại thì order sẽ không được tạo.
Trong kiến trúc Microservices, ta không được mở cánh cổng tại database, bởi khi làm điều đó, ta đã mở toang mọi thứ mà một microservice đang có, kéo theo sự phụ thuộc chặt chẽ lẫn nhau giữa chúng góp phần khó khăn cho việc bảo trì hệ thống sau này. Do đó, ta không thể áp dụng cơ chế two-phase commit giữa các microservice được, chưa kể tới các database trong hệ thống có thể không hỗ trợ điều này.
Saga có thể giải quyết vấn đề này.
Saga không đảm bảo được đầy đủ ACID như một local-transaction mà nó chỉ có thể có ACD. (Tìm hiểu thêm về I - Isolation trong database sẽ ở bài viết khác.)
Sau đây, chúng ta sẽ đi qua sơ lược về Saga Pattern ở các nội dung chính sau:
- Tình huống đặt ra
- Cơ chế hoạt động của Saga
- Đặc điểm của Saga
Để thuận tiện theo dõi, lý thuyết và demo (ở bài viết này) sẽ xoay quanh bài toán minh họa sau:
Bài toán: Tạo mới đơn hàng.
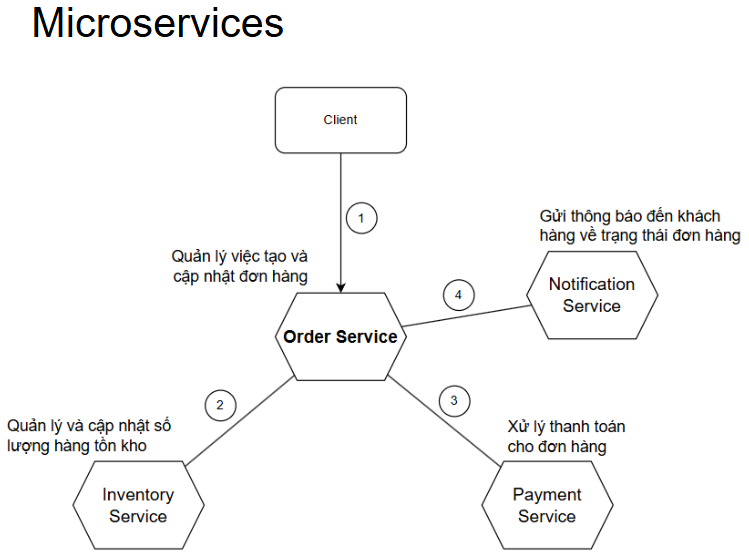
Trong hệ thống của ta có 3 microservices tham gia:
- Order Service: là nơi tiếp nhận yêu cầu tạo mới của người dùng. Mỗi Order được tạo bao gồm nhiều Product với số lượng khác nhau.
- Inventory Service: là dịch vụ quản lý tồn kho của Product. Order Service sẽ gọi Inventory Service để cập nhật tồn kho trong quá trình tạo đơn.
- Payment Service: là dịch vụ thanh toán cho đơn hàng đang được tạo.
- Ngoài ra, còn có Notification Service, chuyên trách gửi thông báo tới người dùng. Phần cho service này ta sẽ bàn tới sau. Với Saga, ta chỉ tập trung vào 3 service trên.
1. Tình huống đặt ra
Với cách xử lý thông thường, một "happy case" sẽ như sau:
- Order Service tiếp nhận yêu cầu, nó cần phải tạo một Order mới và dùng thông tin này để trao đổi với các service khác.
- Order Service gọi sang Inventory Service để cập nhật tồn, giả sử thành công. Tiếp theo
- Order Service gọi sang Payment Service để thanh toán, giả sử thành công. Tiếp theo
- Order Service thông báo cho người dùng qua Notification Service. Tiếp theo
- Order Service lưu dữ liệu Order vào database của nó.
(Sau này bạn sẽ thấy, Order Service đóng vai trò là một Saga Orchestrator.)
Luồng này được mô tả qua sequence diagram sau:
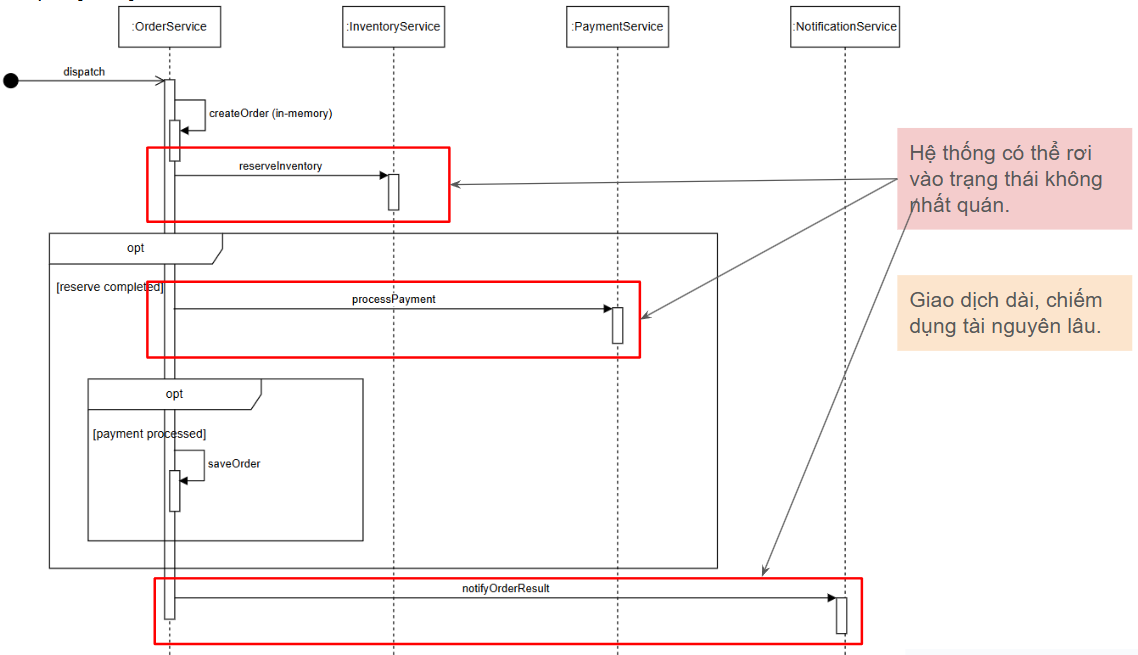
Nhưng có những luồng không thể "happy" được. Giả sử sau khi Inventory Service đã cập nhật tồn kho cho các Product trong Order, nhưng ở bước thực hiện thanh toán tại Payment Service lại không thành công (vì thiếu số dư tài khoản hay vì nguyên nhân nào khác) thì nếu ta không cẩn thận, dữ liệu tồn kho tại Inventory Service sẽ phản ánh sai dữ liệu thực tế. Nó cần phải được hoàn trả số tồn kho ban đầu.
Saga sẽ giúp ta giải quyết vấn đề này.
2. Cơ chế hoạt động của Saga
Saga là cơ chế giúp: Duy trì tính nhất quán của dữ liệu giữa các dịch vụ bằng cách sử dụng chuỗi các giao dịch cục bộ được điều phối thông qua việc giao tiếp bất đồng bộ (asynchronous) giữa chúng. (Tuy nhiên, giao tiếp giữa các service trong Saga không nhất thiết phải là bất đồng bộ.)
Nguyên lý
- Chia nhỏ giao dịch dài thành các giao dịch con nhỏ hơn (gọi là giao dịch thành phần), mỗi giao dịch thực hiện một phần của công việc ban đầu.
- Mỗi giao dịch thành phần là một giao dịch cục bộ, local transaction, và được commit độc lập.
- Một giao dịch thành phần thành công sẽ kích hoạt giao dịch thành phần tiếp theo hoạt động.
- Khi một giao dịch thành phần thất bại, các giao dịch trước đó cần thực hiện các "giao dịch bù trừ - conpensating transaction" để xử lý lỗi. Đây như một bước rollback trong local transaction.
- Saga đảm bảo tính nhất quán cuối cùng - eventual consistency.
Có một điểm lưu ý là "Giao dịch bù trừ", đây là một điều mới nếu bạn hay quen làm trong một database. Trong một database đơn lẻ, khi thực hiện giao dịch, tính chất Atomicity đảm bảo rằng toàn bộ giao dịch dù có chứa nhiều thao tác cập nhật đều được coi là một đơn vị giao dịch duy nhất. Do đó, các thao tác đó hoặc cùng thành công hoặc cùng thất bại. Khi thất bại, database sẽ rollback những thay đổi của giao dịch trước thao tác bị lỗi. Giao dịch bù trừ đóng vai trò tương tự như vậy. Nếu ta có một giao dịch thành phần là reserveInventory thực hiện đặt chỗ, giảm tồn kho cho một đơn hàng, thì ta cần có một giao dịch bù trừ tương ứng rejectReservation để trả lại lượng tồn kho đã giảm khi saga gặp lỗi.
Trong bài toán của chúng ta, giao dịch saga sẽ bao gồm các giao dịch thành phần sau:
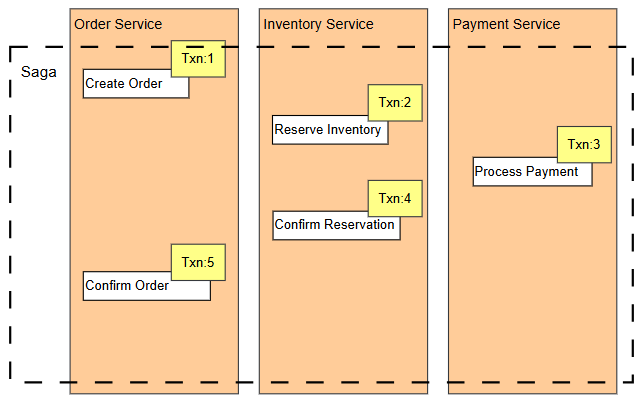
- Txn 1: Order Service thực hiện, tại đó một Order mới được tạo ra.
- Txn 2: Inventory Service thực hiện, tiếp nhận danh sách Product trong Order và thực hiện giảm số lượng tồn nếu thỏa mãn số tồn kho.
- Txn 3: Payment Service thực hiện, tiếp nhận thông tin Order (Customer, Amount) và thực hiện thanh toán.
- Txn 4: Inventory Service thực hiện, xác nhận giao dịch tồn kho trước đó.
- Txn 5: Order Service thực hiện, xác nhận Order là thành công.
Hình 3 là một happy case. Việc thực hiện saga cũng giống như việc leo núi vậy: Bạn đi từ chân núi (Txn 1) lên tới đỉnh (Txn 3) và sau đó đi xuống ở sườn bên kia để xuống lại chân núi (Txn 5). Đây là một kịch bản thành công.
Với nửa sườn núi đầu tiên, tại mỗi bước, nếu giao dịch thành phần tại đó thất bại, bạn cần phải đi ngược lại để xuống chân núi, và tại mỗi bước đã thành công trước đó, bạn phải thực hiện một giao dịch bù trừ để bù trừ lại những gì bạn đã làm trong quá trình leo lên. Đây là kịch bản thất bại.
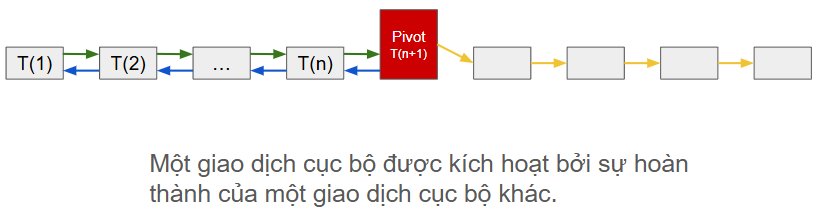
Khi lên tới đỉnh và thực hiện thành công, saga cho rằng nó đã là thành công và việc thực hiện các giao dịch xác nhận sau đó là lẽ đương nhiên. Giao dịch tại đỉnh núi được gọi là "giao dịch chốt - pivot transaction".
Hình dưới đây thể hiện điều này:
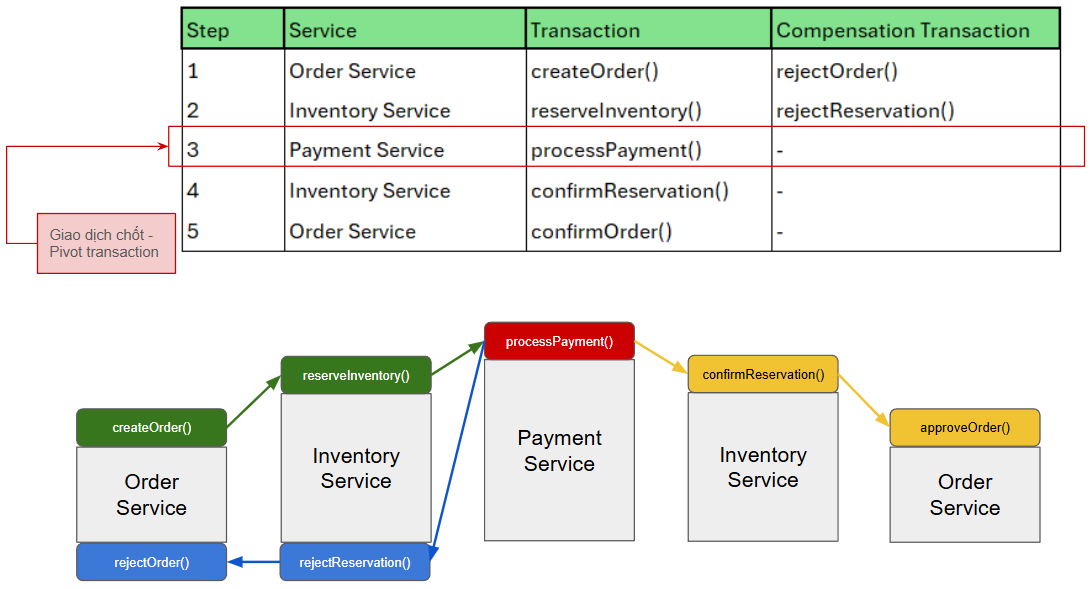
Trong hình 4, ở sơ đồ bên dưới, mũi tên màu xanh lá cây thể hiện giao dịch "leo núi", mũi tên màu xanh lam thể hiện giao dịch "quay đầu xuống núi", còn mũi tên màu vàng là giao dịch "xuống núi ở bên kia sườn núi".
Tổng quát hơn cho luồng thực thi giao dịch bù trừ: Giả sử, saga thực hiện các giao dịch thành phần từ T(1),..., T(n). Nếu giao dịch thành phần T(n+1) gặp lỗi thì saga cần thực hiện giao dịch bù trừ theo thứ tự ngược lại: C(n),..., C(1). Ở đây C(i) là giao dịch bù trừ cho giao dịch thành phần T(i).
Lý thuyết về Saga cơ bản là như vậy, ta tóm gọn lại trong hình 5:
3. Đặc điểm của Saga
Tính nhất quán cuối cùng
Một trong những đặc điểm quan trọng nhất của saga là tính "nhất quán cuối cùng - eventual consistency".
Trong một database, tính nhất quán là một trong 4 tiêu chuẩn ACID, nó quy định rằng dữ liệu hệ thống luôn ở trạng thái hợp lệ và chính xác sau mỗi giao dịch. Ví dụ, bạn thực hiện chuyển tiền từ account này sang account khác thì bạn phải thực hiện 2 thao tác trong một giao dịch: trừ tiền ở account 1 và cộng tiền ở account 2. Nhưng nếu bạn đã trừ tiền ở account 1 xong mà thao tác cộng tiền ở account 2 bị lỗi, bạn không cộng lại tiền cho account 1 hay hủy thao tác trừ tiền của nó, thì hệ thống của bạn sẽ rơi vào trạng thái không nhất quán.
Với giao dịch thành phần, tính nhất quán được đảm bảo rất dễ dàng với cơ chế giao dịch của database. Nhưng với các hệ thống phân tán như Microservices, điều này khó đảm bảo được.
Xem vào hình 3 bên trên, sau khi Txn 2 thực hiện thành công, Inventory Service đã trừ tồn kho rồi nhưng Payment Service chưa thanh toán. Hay ở ngay bước đầu tiên, Txn 1, Order được tạo mà chưa cần biết kho có đủ tồn hàng hóa không.
Đó là những "khoảnh khắc" nhỏ trong saga mà ở đó hệ thống của ta không có sự nhất quán về mặt dữ liệu.
Nhưng cuối cùng, saga sẽ đạt tới điểm kết thúc: thành công hoặc thất bại. Và khi đó, hệ thống của ta sẽ đạt trạng thái nhất quán. Đó chính là tính "nhất quán cuối cùng" của saga.
Không đảm bảo Isolation
Trong database truyền thống, Isolation với các cấp độ khác nhau giúp cho hệ thống của ta có thể đảm bảo được yêu cầu trong tình huống nhiều người dùng đồng thời cùng truy cập vào một tài nguyên.
Ví dụ, ở cấp độ Read Commited trong một SQL database, hiện tượng Phantom Read có thể xảy ra: Trong cùng một giao dịch, ta thực hiện quy vấn dữ liệu với cùng một điều kiện nhưng ở hai thời điểm khác nhau, thì ta có thể nhận được hai kết quả khác nhau. Bởi vì giữa hai lần đọc đó, có một giao dịch khác đã commit một thay đổi trên chính dữ liệu thỏa mãn truy vấn của ta.
Hay ở cấp độ Repeatable Read, giúp ta giải quyết được vấn đề Phantom Read, giao dịch đọc lại nhiều lần cùng một truy vấn vẫn sẽ chỉ có được một kết quả duy nhất như lần đọc đầu tiên.
Tuy nhiên, ở saga transaction, ta không có cơ chế đó, hay nói cách khác, saga không có Isolation. Chính xác thì cấp độ Isolation trong saga là Read Uncommited.
Giả sử có hai saga đang chạy trong hệ thống, cùng là tạo Order như trên. Khi cả hai cùng yêu cầu giảm tồn kho ở Inventory Service, giả sử giao dịch saga 1 thực hiện trước, nó giảm tồn kho của Product 1 từ 100 xuống còn 80. Dù saga 1 về tổng thể là chưa thực hiện xong, thì saga 2 thực hiện ngay sau đó đã thấy được ngay Product 1 đang có tồn kho là 80. Điều này tương tự như Isolation là Read Uncommitted trong database. Đáng lẽ ra, saga 2 khi đó thấy Product 1 vẫn có tồn kho là 100. Ta có ví dụ chi tiết bên dưới.
Các vấn đề gây ra bởi thiếu Isolation
Lost updates
Tính huống được mô tả như trong hình dưới đây:
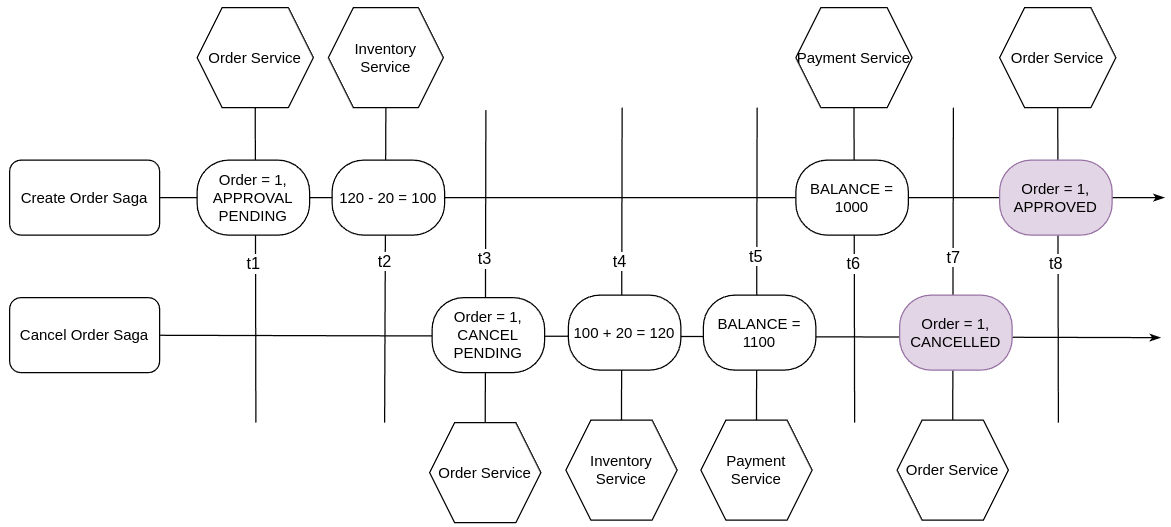
Trong hình 6 trên,
- Trục ngang thể hiện hai saga: Create Order Saga và Cancel Order Saga và thời gian xảy ra tương tác t1, t2, ...
- Trục dọc là các microservices thực hiện hành động tại các thời điểm trên trục thời gian.
- Các hình chữ nhật bo tròn là thông tin dữ liệu chính.
Vấn đề lost update xảy ra như sau:
- Tại thời điểm t1, Create Order Saga tạo ra bản ghi mới với Order Id = 1, trạng thái APPROVAL PENDING.
- Thời điểm t2, Create Order Saga thực hiện gọi Inventory Service để giảm tồn kho của PRODUCT 1 xuống còn 100 sản phẩm.
- Thời điểm t3, Cancel Order Saga được tạo, bản ghi với Order Id = 1 được chuyển về trạng thái CANCEL PENDING.
- Các thời điểm t4, t5, Cancel Order Saga thực hiện liên tiếp các thay đổi như trả lại tồn kho sản phẩm PRODUCT 1 về 120 sản phẩm và tăng lại số dư cho khách hàng lên thành 1100. (Số dư này không phản ánh đúng thực tế.)
- Thời điểm t6, Create Order Saga mới thực hiện giảm số dư tài khoản khách hàng xuống 1000. (Lúc này số dư đã phản ánh đúng thực tế).
- Thời điểm t7, Cancel Order Saga chuyển Order Id = 1 về trạng thái CANCELLED.
- Thời điểm t8, Create Order Saga chuyển Order Id = 1 về trạng thái APPROVED.
Như vậy, giá trị đúng phải là Order có trạng thái CANCELLED do người dùng đã thực hiện hủy đơn hàng. Trạng thái này đã bị ghi đè.
Nếu bạn thấy cách mô tả của tôi quá rắc rối thì tôi tóm lược lại như sau:
- Create Order Saga tạo ra Order với ID = 1. Trạng thái Order đang là APPROVAL PENDING. Trong lúc saga này đang thực hiện thì có cập nhật
- Hủy đơn, và do đó, Cancel Order Saga được tạo ra. Và saga này chạy nhanh hơn Create Order Saga nên nó chuyển trạng thái APPROVAL PENDING về CANCELLED.
- Sau đó, Create Order Saga mới chạy xong và chuyển đơn từ CANCELLED sang APPROVED.
Dirty reads
Trong một SQL database, dirty reads chính là tương ứng với mức Isolation READ UNCOMMITTED. Khi đó, các giao dịch có thể đọc được dữ liệu chưa commit của nhau.
Tiếp tục ví dụ từ hình 6, ta có hình 7 như sau:
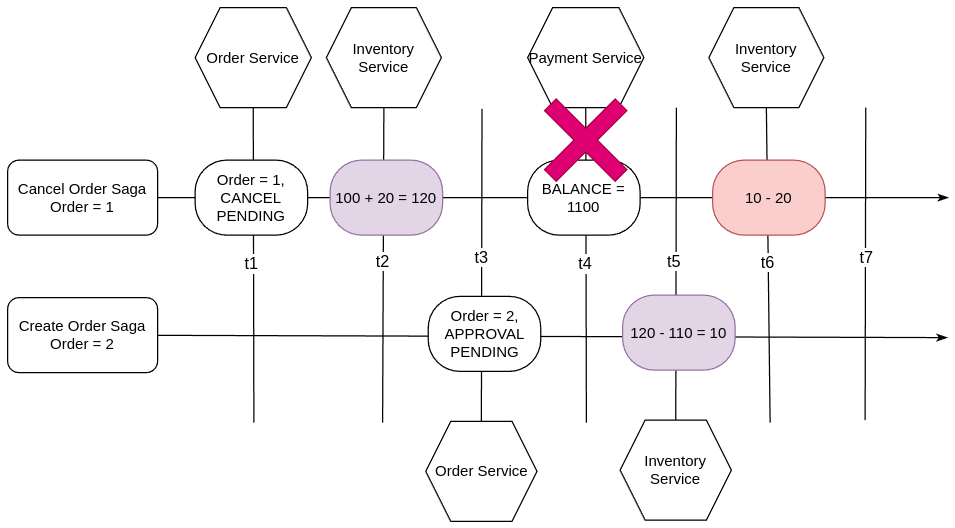
Trong hình 7,
- Tại thời điểm t1, một Cancel Order Saga được tạo ra để hủy đơn hàng OrderID = 1.
- Thời điểm t2, Cancel Order Saga gọi giao dịch trả lại số tồn kho cho sản phẩm, 100 + 20 = 120 đơn vị.
- Thời điểm t3, một Create Order Saga khác được sinh ra và nó cũng chứa cùng sản phẩm với Order 1. Đơn hàng OrderID = 2 có trạng thái APPROVAL PENDING.
- Thời điểm t4, Cancel Order Saga đang thực hiện bù trả lại tiền cho khách hàng thì bị lỗi. Do đó, saga này cần thực hiện luồng gọi giao dịch bù trừ của nghiệp vụ Cancel Order.
- Thời điểm t5, Create Order Saga thực thi tại Inventory Service, thực hiện giảm số tồn kho của sản phẩm với 120 - 110 = 10 đơn vị.
- Thời điểm t6, Cancel Order Saga thực hiện giao dịch bù trừ tại Inventory Service, nó cần phải giảm lại số tồn kho của Order 1 bằng cách giảm đi 20 đơn vị. Nhưng lúc này, tồn kho chỉ còn 10 nên giao dịch này lỗi.
Một lần nữa, nếu bạn thấy tôi trình bày quá rối thì tôi lại tóm tắt lại ví dụ này như sau:
- Đầu tiên là đơn Order = 1 bị hủy. Luồng này thực hiện trả lại số tồn kho.
- Ngay sau đó, có đơn Order = 2 được tạo và số tồn kho lúc này được trừ đi.
- Nhưng luồng hủy gặp lỗi ở thanh toán trả lại tiền tại Payment Service nên số tồn kho cần phải giảm lại do đơn không được hủy nữa. Nhưng do số tồn không đủ nên không giảm được.
Đây là hiện tượng dirty reads của Saga.
Cách khắc phục
Do sự thiếu vắng Isolation trong Saga nên chúng ta, những lập trình viên, cần có một số thao tác để ngăn chặn hoặc giảm thiểu điều này.
Ta có một số cách khác nhau.
Semantic lock - khóa ngữ nghĩa
Đây là cách thường thấy để khắc phục vấn đề của Saga. Ngay trong ví dụ này, bạn thấy có các trạng thái của đơn hàng là APPROVAL PENDING, APPROVED, CANCELLED. Các giá trị này có thể được dùng làm semantic lock cho bản ghi.
Với ví dụ trong hình 6, bản ghi đang ở trạng thái APPROVAL PENDING thì với thao tác hủy đơn hàng ngay sau đó, hệ thống có thể xử lý một trong hai cách sau:
- Không xử lý và thông báo thử lại với người dùng.
- Xếp hàng đợi cho yêu cầu này, chờ semantic lock được giải phóng (khi đó, đơn hàng có trạng thái APPROVED hoặc REJECTED) thì xử lý.
Tương tự với ví dụ trong hình 7, bạn có thể đặt một semantic lock cho bản ghi trên sản phẩm đang trong quá trình xử lý bởi một saga.
Commutative updates - các phép cập nhật giao hoán
Nhìn tên ta có thể mường tượng: các phép toán cập nhật có thể thay đổi vị trí mà không làm mất đi tính đúng đắn toàn cục.
Ví dụ, phép toán tăng và giảm tồn kho cho sản phẩm có thể coi là giao hoán: ta có thể thực hiện chúng trước hay sau cái còn lại thì kết quả cuối cùng vẫn là như nhau.
Ví dụ trong hình 7, ta có thể sử dụng phương pháp này tại Inventory Service.
Tuy nhiên, có một vấn đề cần chú ý: Số tồn kho có thể âm nếu ta không có logic bổ sung. Một giải pháp cho vấn đề này là ta có thể đặt một giới hạn tồn kho nhất định.
Trong thực tế, với những dịch vụ mà bạn có thể "tự tin" cập nhật số dư sớm nếu phát sinh âm thì các hạn chế này có thể được loại bỏ.
Pessimistic view - "đời thường là máu xám"
Với cách xử lý này, ta sắp xếp lại những bước trong saga để giảm khả năng xảy ra dirty read: Những bước ít rủi ro hơn lên trước bước rủi ro lớn hơn.
Tuy nhiên, cách thức này không phải lúc nào cũng thực hiện được, do tùy thuộc vào yêu cầu nghiệp vụ.
Ví dụ với bài toán trong hình 6, ta có thể thay đổi như sau:
- Đầu tiên, cập nhật trạng thái đơn hàng thành CANCELLED trong Order Service.
- Tiếp theo, hủy giao hàng (thông báo tới dịch vụ giao hàng).
- Tiếp theo, trả lại tồn kho mà đơn hàng đang giữ tại Inventory Service.
- Cuối cùng, trả lại số tiền thanh toán cho khách hàng tại Payment Service.
Reread value - Một cơ chế Optimistic Locking
Reread value là phương pháp giống với Optimistic Offline Lock Pattern, ở đó, nếu bản ghi ta định cập nhật mà có thay đổi so với lúc ta đọc nó lên thì ta sẽ không cập nhật nữa. Đây là phương pháp rất hiệu quả để chống lại vấn để Lost Updates.
Với ví dụ trong hình 6, khi Create Order Saga đang trong quá trình xử lý cập nhật lại trạng thái đơn hàng ở thời điểm t8, nếu nó thấy rằng đơn hàng này đã bị thay đổi thì nó không cập nhật nữa và kích hoạt quá trình xử lý bù trừ. Ngược lại, nó cập nhật thành công.
Để làm được điều này, trong mỗi dịch vụ thành phần cần phải có một cơ chế versioning cho dữ liệu. Thông tin version này có thể là một cột version integer, một cột update timestamp.
Version file
Với các nghiệp vụ bao gồm các phép toán không giao hoán, ta có thể áp dụng phương pháp này.
Cách thức này có những yêu cầu sau:
- Hai hay nhiều saga đang thao tác trên cùng một đối tượng nghiệp vụ gốc, ví dụ ở đây là OrderID (= 1).
- ID của dữ liệu (hay Aggregate ID) và trạng thái phải được lưu trong service thành phần, ví dụ ở đây là OrderID (=1) và OrderStatus (=APPROVAL PENDING).
Đây là phương pháp tránh lost updates bên trên.
Với ví dụ hình 6 bên trên:
- Khi Create Order Saga thực thi tại Inventory Service, nó tạo một bản ghi trong Version File liên quan đến
OrderID = 1với trạng thái làAPPROVAL PENDING. Bản ghi này sẽ giúp Inventory Service ghi nhớ rằng đơn hàng này đang trong quá trình phê duyệt và cập nhật tồn kho. - Khi Cancel Order Saga gửi yêu cầu tới Inventory Service để hủy đơn hàng với
OrderID = 1và trạng thái làCANCEL PENDING, Inventory Service sẽ kiểm tra Version File. Nếu phát hiện rằngOrderID = 1đã có trạng thái làAPPROVAL PENDING, Inventory Service sẽ từ chối thực thi yêu cầu hủy tồn kho của Cancel Order Saga. - Điều này giúp ngăn chặn sự ghi đè dữ liệu không mong muốn giữa hai saga, đảm bảo rằng trạng thái tồn kho chỉ được cập nhật một cách nhất quán và theo đúng thứ tự.
By value - theo giá trị nghiệp vụ
Chữ "value" trong này không phải là các con số thể hiện bản ghi mà là "Giá trị nghiệp vụ - Business value". Theo đó,
- Những nghiệp vụ nào yêu cầu quản lý rủi ro thấp, tức nếu có sai sót cũng không gây tổn thất đáng kể, thì có thể áp dụng saga cùng với các biện pháp bên trên.
- Ngược lại, những nghiệp vụ nào yêu cầu quản lý rủi ro cao, tức nó có giá trị nghiệp vụ cao và đòi hỏi sai sót thấp, thì cần các biển pháp khác mạnh mẽ hơn distributed transactions (như two-phase commit).
4. Kết luận
Như vậy, trong bài viết này, chúng ta đã đi qua những khía cạnh quan trọng nhất của một Saga Transaction. Trong bài, chúng ta chưa bàn về cách thực thi chúng. Thực tế, ta có hai cách là Saga Choreography và Saga Orchestration.
Bài tiếp theo sẽ là một hướng để thực thi Saga Orchestration.