

Giới thiệu
Là thiếu sót khi tôi không có những bài viết mang tính thiết kế, hoạch định hệ thống ở cấp cao hơn – cấp chiến lược, mà lại đi ngay vào những thành phần mang tính nhỏ lẻ của DDD như Entity, Value Object, Factory, Aggregate,… Điều này mang dụng ý xuất phát từ kinh nghiệm khi tiếp cận DDD. Những khái niệm như Domain, Subdomain, Bounded Context, Continuous Integration, hay Event Storming thường mơ hồ và kém hấp dẫn hơn những Entity, Value Object, hay Aggregate,… Không những vậy, để quen, hiểu, và áp dụng được cũng cần tích lũy kinh nghiệm từ lý thuyết tới thực hành. Đó là một chặng đường có thể tính bằng tháng, bằng năm.
Do đó, tôi lựa chọn cách tiếp cận mà theo cá nhân là thực tế hơn: Hiểu từ những khái niệm cơ bản, sau đó dần đi tới những khái niệm lớn hơn. Những thứ cơ bản đó ta gọi là Tactical Design, còn những thứ lớn là Strategic Design. Ngày nay, ai ai cũng nghĩ về triển khai Microservices và đa số đặt mối quan tâm tới hoạch định ranh giới giữa các service. Ở phần Strategic Design sau này, bạn sẽ có thêm một công cụ xác định xem trong Domain của mình cần có những service nào để tạo nên một kiến trúc Microservices.
Kiến trúc Microservices được hình thành bởi một tập rất nhiều các micro-service – là những service rất nhỏ. Nhưng thế nào là nhỏ? Ta thường phân chia service theo cảm tính: ta gom các chức năng “có vẻ” có cùng nghiệp vụ lại với nhau thành một service. Điều này không sai, chỉ là ta cần thứ gì đó giúp giảm tính “cảm tính” đi thôi.

Hình 1: Quy trình tạo đơn hàng xảy ra trong ứng dụng Monolithic trở nên đơn giản
Kiến trúc Monolithic trong hình 1, quy trình tạo mới đơn hàng giúp nhiều thứ trở nên đơn giản và dễ kiểm soát hơn. Ở đó, các bước kiểm tra tồn kho hay thanh toán đều nằm trong cùng một ứng dụng sẽ giúp hiệu năng cao hơn (ở một ngưỡng dữ liệu) do các lời gọi là local, không cần qua tầng network, dữ liệu được đảm bảo ACID vì chúng cùng một database.

Hình 2: Chuyển sang mô hình phân tán, quy trình tạo đơn đã được chia ra cho nhiều dịch vụ phụ trách, việc giao tiếp là bắt buộc để hoàn thành quy trình ngày
Kiến trúc Microservices là một dạng kiến trúc phân tán, mà khi đã phân tán thì các quy trình nghiệp vụ cũng bị phân tán ra nhiều nơi. Hình 2 cho thấy cũng là quy trình tạo mới đơn hàng nhưng các lời gọi đã không còn là cục bộ nữa, chúng phải có network hỗ trợ. Lúc này nhiều rủi ro xuất hiện như tính sẵn sàng của network, tính sẵn sàng của những service thành phần và tính nhất quán dữ liệu chung của hệ thống,… Lúc này, taa phải thực hiện một công việc tưởng chừng đơn giản mà rất phức tạp, tốn kém nhiều nguồn lực từ con người cho tới tài nguyên hệ thống: Tích hợp dữ liệu – tích hợp giữa các microservice để sao cho chúng đảm bảo hoàn thành được toàn vẹn các quy trình kinh doanh.
Có thể đa số chúng ta đã tham gia phát triển những dịch vụ cần phối hợp, trao đổi dữ liệu với những dịch vụ khác để hoàn thành nhiệm vụ của nó. Giao tiếp chúng ta thường cài đặt là API Synchronization. Bỏ qua các ưu nhược điểm của cách này vì ta đã có trong bài khác, hãy nghĩ về ý nghĩa của giao tiếp dạng này. Order Service tiếp nhận yêu cầu xử lý đơn hàng từ UI, nó tạo ra Order rồi tiếp tục gọi tới Inventory Service để kiểm tra tồn kho và cuối cùng là thực hiện thanh toán tại Payment Service. Quy trình xử lý này, tuy được phân tán ra ba services khác nhau nhưng nó vẫn là một biến thể của Monolithic: thay vì ba xử lý thành phần chạy trên cùng một CPU thì giờ nó chuyển thành ba CPU khác nhau, và do đó các chi phí khác tăng lên (network, HR resources,…) mà các bước vẫn bị gắn kết chặt chẽ với nhau làm cho nhiều chỉ số chất lượng tổng quan của hệ thống giảm đi như hiệu năng, khả năng sẵn sàng, ...
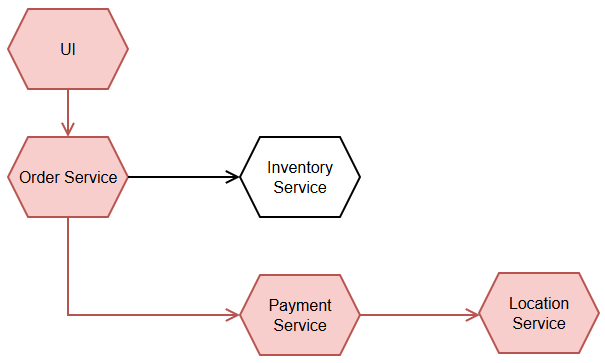
Hình 3: Một góc của Distributed Monolith
Order Service còn cần phải biết quy trình kinh doanh: Để hoàn thành một order, nó cần phải gọi tới Inventory Service và Payment Service. Và cứ như thế, dịch vụ nào cũng cần phải biết tường tận quy trình xử lý mà nó là nhân tố tiếp nhận đầu tiên. Đội ngũ phát triển phụ trách các dịch vụ đó nếu không có tài liệu thiết kế sẽ bị ngộp trong một mớ bòng bong quy trình nghiệp vụ được thể hiện trong source code và do đó là cả tích hợp hệ thống. Đó là còn chưa kể có những thứ không liên quan tới quy trình nghiệp vụ mà dịch vụ của ta vẫn phải gọi như logging, chèn thông tin cần thiết sang một dịch vụ khác quản lý, ... Tóm lại, đây là một dạng tích hợp chủ động, nơi mà mỗi dịch vụ cần biết toàn bộ những dịch vụ khác cần dữ liệu từ nó để nó gửi sang.
Domain Event giúp ta giảm nhẹ vấn đề trên – một trong những mục tiêu của nó. Order Service tạo ra Order. Để những dịch vụ quan tâm tới việc một Order mới sinh ra, nó phát hành một sự kiện OrderCreated. Như vậy, thay vì chủ động “điền tên” các dịch vụ trong quy trình xử lý, Order Service cần thông báo ra xung quanh. Cuối cùng, điều gì giúp Order Service biết rằng Order vừa tạo đạt trạng thái thành công hay thất bại? Thành công khi các bước trong quy trình đều thành công, thất bại khi một phần trong đó là thất bại. Câu trả lời ngắn gọn: Order Service tuy rằng không cần biết ai tham gia vào quy trình xử lý nhưng điều nó cần biết là những sự kiện thông báo kết quả xử lý của mỗi bước. Hình 4 bên dưới cho thấy điều này.
Về phía các bước xử lý – tác giả của những sự kiện phản hồi mà Order Service lắng nghe, chúng cần làm gì? Inventory Service và Payment Service cần biết sự kiện kích hoạt nghiệp vụ xử lý của chúng, ở đây là OrderCreated, cũng có thể thêm OrderFailed để chúng có thể “rollback”. Sau khi xử lý xong phần việc, chúng cũng cần thông báo qua những Domain Event, ví dụ như InventoryChecked, InventoryCheckFailed, PaymentChecked, hay PaymentCheckFailed, …
Mọi thứ diễn ra một cách nhịp nhàng thông qua cơ chế truyền tin – một thành phần đóng vai trò mạch máu trong hệ thống Event-Driven. Hình 4 thể hiện ý tưởng này.

Hình 4: Order Service lúc này chỉ quan tâm tới những Domain Event ảnh hưởng tới quy trình nghiệp vụ của nó, ví dụ như InventoryChecked, PaymentProcessed, InventoryCheckFailed, … mà không cần biết, phía sau ai là người xử lý
Domain Event không chỉ đóng vai trò tích hợp như bên trên mô tả, nó còn có thể trở thành hộp đen ghi nhận lịch trình hệ thống. Sử dụng các cơ chế publishing events tin cậy như Transactional Outbox, Log-based, mỗi service tự lưu trong nó những sự kiện quan trọng xảy ra trong hệ thống và đảm bảo không bao giờ mất đi. Việc này rất quan trọng. Bạn thử hình dung, với mô hình truyền thống, dữ liệu thường được cập nhật ngay với thao tác người dùng. Giả sử, chỉ vì hiểu sai nghiệp vụ hay xảy ra sự cố mất dữ liệu, khả năng recover dữ liệu đúng là cực kỳ khó khăn, nhất là khi dữ liệu đó được sinh ra do nghiệp vụ từ dữ liệu khác yêu cầu. Với những dịch vụ được xây dựng dựa trên event, hay Event-Sourcing, ta có thể tìm ra nơi lưu trữ events và chạy lại. Dù không dễ dàng nhưng dù sao, với cơ chế này, mọi thay đổi trong hệ thống đã được lưu lại, và qua đó, dữ liệu có thể được replay từ lúc nó bắt đầu cho tới trạng thái cuối cùng hiện tại. Thêm nữa, Domain Event còn có tác dụng lớn trong những hệ thống cần thực hiện audit thường xuyên, đảm bảo tuân theo các chính sách phát triển an toàn, bảo mật dữ liệu người dùng cũng như kinh doanh.
Động lực sử dụng event là rất rõ ràng, trong DDD điều này cũng không hề mất đi hay giảm nhẹ. DDD và Microservices Archiecture có rất nhiều điểm khiến chúng phối hợp ăn ý với nhau. Một tổ chức kinh doanh trong một lĩnh vực, ta gọi là Domain - chính là "Domain" trong DDD. Để phục vụ các mục tiêu trong Domain đó, họ phải chia thành nhiều Subdomain. Trong hệ thống Ecommerce mà ta dùng làm ví dụ, một số Subdomain có thể là Order-Subdomain (chuyên về quản lý đơn hàng), Shipment-Subdomain (chuyên về vận chuyển đơn), ... Mỗi Subdomain đó lại được chia thành các Bounded Context khác nhau - là những thành phần chứa bên trong chúng những mô hình logic nghiệp vụ độc lập. Thông thường và thuận lợi nhất, mỗi Bounded Context sẽ trở thành một Microservice. Do đó, với Microservices Architecture, tích hợp các service lại với nhau là cấp thiết thì với DDD, tích hợp Bounded Context cũng cấp thiết không kém. Thậm chí, đứng trên quan điểm nghiệp vụ và kiến trúc thuần túy, DDD còn mang ý nghĩa quyết định, tiên quyết hơn. Chúng ta sẽ không đi sâu vào các cơ chế tích hợp giữa các Bounded Context trong bài này nhưng cần nhớ rằng việc tích hợp là không thể tránh khỏi và nó thể hiện sự phân chia nghiệp vụ tự nhiên trong mô hình kinh doanh mà ta đang cố gắng mô hình hóa.
Cơ chế
Như vậy, Domain Event đóng vai trò thiết yếu trong DDD, ta cần mô hình hóa chúng và đặt chúng ngang hàng với các thành phần khác mà chúng ta đã xem qua. Module nghiệp vụ thông thường sẽ có các thành phần: Entities, Value Objects, Factories, Repositories, Aggregates, và Domain Events.
Với những ai chưa biết về Domain Event, các câu hỏi thường gặp sẽ là:
- Domain Event chứa những thông tin gì?
- Khi nào thì tạo ra chúng?
- Công bố, hay publish nó như thế nào?
- Tiêu thụ, hay consume nó ra sao?
Chúng ta sẽ dần làm rõ các băn khoăn này qua bài này và một số bài khác (do một số câu hỏi cần có mục riêng để trả lời).
Domain Events chứa những thông tin gì?
Domain Event thông báo một điều gì đó mà Domain Experts quan tâm – điều mà Eric Evans đã đề cập, một đề cập ngắn gọn.
Thông báo này có thể là một thông báo ngắn gọn như “Có một Order mới được tạo, OrderID = 12345”. Hay có thể nhiều thông tin hơn một chút như “Order vừa được cập nhật địa chỉ giao hàng. OrderId = 12345, Address = “Số nhà 123, đường …”” . Hay có thể nhiều hơn nữa như “Order vừa được cập nhật. OrderId = 12345, Address = “…”, CustomerId = 234, …” Có khá nhiều lựa chọn nội dung của Domain Events mà ta cần xem xét, mỗi cách mang tới những ưu nhược điểm khác nhau.
Thông tin tối giản
“Có một Order mới được tạo, OrderID = 12345” hay “Order vừa được cập nhật địa chỉ giao hàng. OrderId = 12345, Address = “Số nhà 123, đường …”” là những ví dụ về thông tin tối giản mà Domain Event có thể mang theo. Có một dạng còn tối giản hơn nữa nhưng ít được sử dụng, ví dụ “Có một Order vừa được tạo”!!!
Cấu trúc Domain Event và Notification (giả sử để gửi tới người dùng) tương ứng như sau:

Với những thông tin tối giản như vậy ưu điểm là rất rõ ràng:
- Thông tin súc tích, trực diện. Ví dụ “Order vừa được cập nhật địa chỉ giao hàng. OrderId = 12345, Address = “Số nhà 123, đường …”” Event cho thấy Type = DeliveryAddressChanged, Order bị thay đổi địa chỉ có ID = 12345, thông tin địa chỉ mới là “Số nhà 123, đường …” Thông tin như vậy thể hiện rõ quy trình nghiệp vụ trong Domain: Có chức năng tạo mới đơn hàng, có chức năng cập nhật địa chỉ giao hàng.
- Xử lý events nhanh hơn, tiết kiệm hơn. Do events nhỏ gọn nên quá trình serilization/deserialization đều nhanh hơn, hạ tầng mạng bị chiếm băng thông ít hơn, các message queue cũng cần ít tài nguyên lưu trữ hơn.
Nhược điểm cũng được thể hiện:
- Các dịch vụ consume events này có thể cần thêm thông tin đơn hàng để xử lý. Ví dụ, tại Shipment Service – dịch vụ chịu trách nhiệm lập kế hoạch và vận chuyển đơn hàng, tiếp nhận DeliveryAddressChanged event, ngoài địa chỉ mới trong event, nó còn cần các thông tin khác như danh sách sản phẩm trong đơn hàng, khối lượng đơn hàng, hoặc thông tin gì đó khác. Có 2 hướng để Shipment Service xử lý: Một là, nó phải duy trì trạng thông tin Order từ khi khởi tạo cho tới khi giao hàng xong – tức hoàn thành quy trình của nó (xem tại phần Thông tin đầy đủ bên dưới), hai là, nó phải truy vấn ngược lại Order Service để lấy thông tin cần. Cách hai được mô tả như trong hình 6.

Hình 6: Shipment Service cần gọi ngược lại Order Service để lấy thông tin đầy đủ
Hình 6 cho thấy luồng xử lý như sau. (1) Order Service thay đổi địa chỉ giao hàng và phát ra sự kiện DeliveryAddressChanged. (2) Shipment Service lắng nghe sự kiện đó, có được OrderId trong tay, nó thực hiện lời gọi (3) tới Order Service để lấy thông tin đơn hàng qua cơ chế sync. Shipment Service phụ thuộc đồng bộ vào Order Service, vì thế các rủi ro về giao tiếp đồng bộ lại xuất hiện như tính sẵn sàng, lỗi dây chuyền. Ngoài ra, nếu Shipment Service mở rộng theo chiều ngang, nó cũng gây ảnh hưởng tới Order Service và khiến Order Service cần mở rộng theo. Gần giống Distributed Monolith phải không? Thêm nữa, thông tin Event có thể không cập nhật so với API Sync.
Để khắc phục vấn đề này, ta cần kết hợp cả hai cách: Event đầy đủ và Event tinh gọn. Chính là hướng 1 đã nêu phía trên của Shipment Service: Cần duy trì thông tin Order từ khi khởi tạo cho tới khi giao hàng xong.
Thông tin đầy đủ
(Kết hợp Thông tin đầy đủ + Thông tin tối giản thì đúng hơn.)

Hình 7: Shipment Service lắng nghe nhiều loại event mà Order Service phát ra để duy trì thông tin Order cần thiết
Theo hình 7, (1) Order Service phát ra event tạo mới đơn hàng ngay sau khi đơn hàng được tạo, OrderCreated. OrderCreated mang đầy đủ thông tin Order vừa được tạo. (2) Shipment Service tiếp nhận OrderCreated, tạo một lớp Anti-corruption Layer để đảm bảo thông tin Order cần thiết cho nó. Kết quả là một Order được thêm vào trong Shipment Service. (3) Order Service cập nhật địa chỉ giao của đơn và phát ra DeliveryAddressChanged event. (4) Shipment Service lấy về rồi từ OrderId, nó lấy lên Order đang sở hữu rồi cập nhật địa chỉ giao mới. Như vậy, với luồng xử lý này, Shipment Service không cần truy vấn ngược lại Order Service để lấy đầy đủ thông tin Order.
Chú ý rằng, Order tại Order Service và Order tại Shipment Service là hai mô hình nghiệp vụ khác nhau dù chúng cùng tham chiếu tới một OrderId.
Cách thiết kế này gây thách thức về tài nguyên dịch vụ lưu trữ do thông tin, theo một khía cạnh nào đó, đã được duplicate trên nhiều dịch vụ. Tuy nhiên, đây dường như không phải là vấn đề lớn do chi phí lưu trữ hiện nay không còn quá đắt đỏ. Thách thức thực sự đến từ việc làm thế nào để duy trì thông tin nhất quán tại nhiều nơi. Một khi xảy ra sự thiếu nhất quán, ta cần phải cập nhật hoặc loại bỏ dữ liệu đó. Việc loại bỏ là dễ dàng nhưng cần đánh giá mức độ ảnh hưởng xem dữ liệu bị sai lệch đó nếu bị bỏ qua có ảnh hưởng gì tới kết quả chung không. Còn khi xác định cần cập nhật lại, với kiến trúc truyền thống là khó khăn nhưng với thiết kế Event Sourcing, ta có thể chạy lại sự kiện tại một consumer để tái tạo lại trạng thái update cho nó. Dù có những rủi ro ảnh hưởng tới những dịch vụ khác khi chạy lại sự kiện nhưng nếu có sự bóc tách, phân chia ranh giới đủ tốt, điều này có thể giảm thiểu. Thường thì ta nên triển khai Anti-corruption Layer để đảm bảo chỉ có những thông tin cần thiết mới lọt vào dịch vụ của ta.
Xem tiếp phần 2 tại đây.