

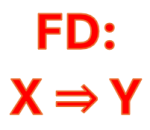

Sự ra đời của Relational Database
Ra đời vào những năm 1970 của thế kỷ trước, Relational Database - RD (Cơ sở dữ liệu quan hệ) đã trải qua một hành trình dài xây dựng và trưởng thành. Hiện nay, RD vẫn đóng vai trò là cơ sở dữ liệu chính trong những ứng dụng đòi hỏi tuân thủ chặt chẽ các quy tắc về tính toàn vẹn dữ liệu. Một số ưu điểm của chính RD:
- Tính ổn định và tin cậy cao.
- Tính chất ACID chặt chẽ.
- Ngôn ngữ truy vấn SQL đầy đủ.
Trước khi RD ra đời, người ta thường phải làm việc với những cơ sở dữ liệu cứng nhắc mà ở đó cấu trúc lưu trữ phản ánh chính mục đích truy vấn của bài toán. Có thể kể đến như Hierarchical Database và Network Database.
Năm 1970, Edgar F. Codd đã công bố một bài báo mang tính đột phá "A Relational Model of Data for Large Shared Data Banks". Trong bài báo, Codd đã giới thiệu mô hình cơ sở dữ liệu gọi là Relational Model - Mô hình cơ sở dữ liệu quan hệ, ý tưởng chính là:
Nếu bỏ qua cách các file liên kết với nhau và sắp xếp dữ liệu dưới dạng hai chiều, không có thứ tự, thì ta có thể phát triển một phép tính cho các truy vấn và tập trung vào dữ liệu dưới dạng đúng là dữ liệu chứ không phải dưới dạng thể hiện vật lý của một mô hình logic.
Như vậy, Codd tập trung vào dữ liệu ở mức logic hoàn toàn, thể hiện ở hai ý:
- Ta không cần quan tâm tới cách mà dữ liệu được lưu trữ, mức vật lý.
- Dữ liệu ở dạng bảng hai chiều, không có thứ tự giữa các dòng và mọi dòng đều có tính duy nhất.
Codd dựa trên hai lý thuyết:
- Lý thuyết tập hợp (set theory). Ở đây, ông coi các bảng (quan hệ, hay relation) là các tập hợp của các bản ghi (tuples). Tập hợp là một nhóm các phần tử không trùng lặp, chứa một tập Head - là tập các Attributes - Thuộc tính, tập con là tập các attributes của bảng.
- Lý thuyết đại số quan hệ. Đại số quan hệ là một tập hợp các phép toán được định nghĩa trên các relation, cho phép thao tác và truy vấn dữ liệu trong cơ sở dữ liệu một cách hiệu quả. Đây là nền tảng để xây dựng ngôn ngữ SQL.
Ví dụ, giả sử ta có bảng Customers với các thuộc tính như CustomerID, CustomerName, Email. Khi chuyển về ngôn ngữ RD, ta có tương ứng:
- Relation: Customers.
- Attributes: CustomerID, CustomerName, Email.
- Tuples: là các row data của Customers: (1, Nguyễn Văn Sinh, sinhnv@example.com), (2, Phạm Hữu Hảo, hao123@example.com)
Các phép toán chính trong đại số quan hệ:
- Projection - phép chiếu: Lấy ra các thuộc tính cụ thể từ một relation, tương ứng với mệnh đề SELECT của SQL.
- Selection - phép chọn: Lọc các tuple trong một relation dựa trên điều kiện nhất định, tương ứng với mệnh đề WHERE trong SQL.
- Union - phép hợp: Hợp dữ liệu của hai relation có cùng cấu trúc lại với nhau, tương ứng với mẹnh đề UNION trong SQL.
- Join - phép kết: Là phép toán phổ biến nhất trong đại số quan hệ, cho phép kết hợp hai bảng dựa trên một điều kiện chung, tương ứng với mệnh đề JOIN trong SQL.
Quy trình mô hình hóa dữ liệu
Quy trình mô hình hóa dữ liệu là quy trình chuyển yêu cầu người dùng thành các bảng trong một hệ quản trị cơ sở dữ liệu nhất định. Quy trình này phức tạp, được chia thành ba giai đoạn chính. Cụ thể hơn về quy trình này sẽ được bàn bạc sâu hơn ở những bài viết khác. Ba giai đoạn chính bao gồm:
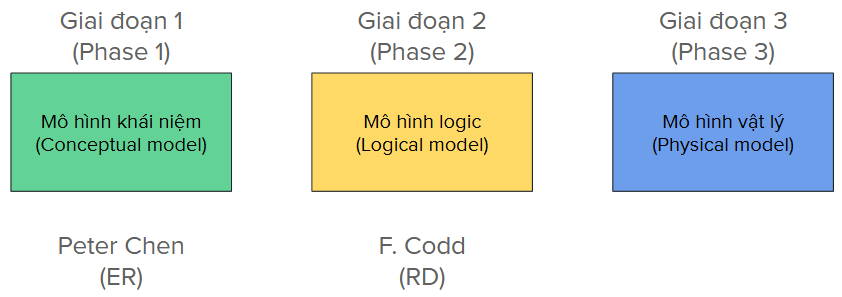
Trong thực tế, có thể bạn không để ý tới các phase này, đặc biệt là phase 1.
- Phase 1 - Mô hình hóa mức khái niệm: Đây là giai đoạn người phân tích tiếp nhận yêu cầu và xác định các thực thể và các mối quan hệ giữa chúng. Kết quả của giai đoạn này là một mô hình khái niệm, thường là mô hình thực thể - liên kết (ER). Người đã tạo ra phương pháp luận ER là Peter Chen. Hình bên dưới là một ví dụ về mô hình ER.
- Phase 2 - Mô hình hóa mức logic: Giai đoạn người thiết kế chuyển mô hình khái niệm ER thành mô hình logic RD mà Codd đưa ra: Đưa các thực thể và mối quan hệ vào các bảng hai chiều thuần túy, xác định khóa và thực hiện chuẩn hóa dữ liệu theo các cấp độ khác nhau (Normal Forms).
- Phase 3 - Mô hình hóa mức vật lý: Giai đoạn này, mô hình logic đã gần sát với mô hình vật lý, chỉ khác là người phát triển cần cụ thể hóa mô hình logic bằng các thao tác: lựa chọn một hệ quản trị cơ sở dữ liệu (RDBMS) phù hợp, rà soát truy vấn có tiềm năng của người dùng và thêm vào đó các index, hay thực hiện partitioning cho dữ liệu trong bảng. Ngoài ra, các kỹ thuật như lưu trữ dư thừa cũng có thể được áp dụng.
Ví dụ về một mô hình ER:
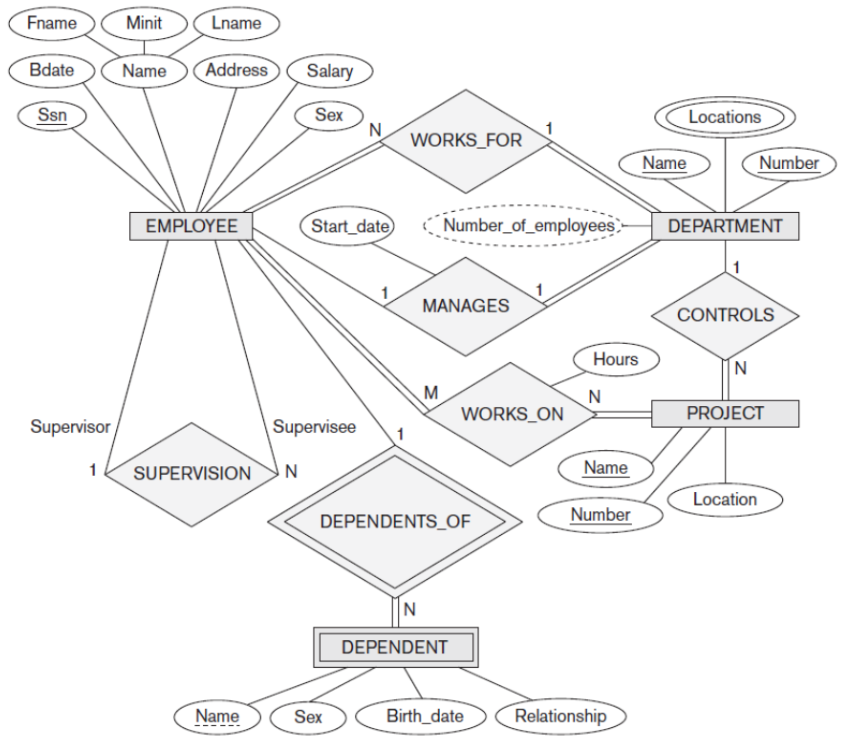
Trong thực tế, bạn thường bỏ qua giai đoạn mô hình hóa khái niệm và đi vào ngay mô hình hóa logic hoặc vật lý. Thực ra, bạn vẫn dùng nó đấy: đó chính là việc bạn cùng với BAs, End Users phân tích yêu cầu với nhau thông qua tài liệu hay trong các buổi meeting. Chỉ khác là, sản phẩm mà bạn trưng bày ra cho họ sau những buổi trao đổi đó là mô hình logic. Với những yêu cầu nghiệp vụ đơn giản (thường đồng nghĩa với mô hình logic đơn giản) thì khác hàng của bạn (tức là BAs, End Users) vẫn có thể nắm bắt được ý tưởng, nhưng nếu đó là những yêu cầu phức tạp thì sao? Liệu bạn có hi vọng họ hiểu hết ý tưởng mô hình hóa của bạn khi xem vào các bảng được liên kết với nhau thông qua các khóa ngoại, các bảng trung gian, tất cả được đặt trong một bức tranh chi tiết: Database Schema? Đó là những kẽ hở khiến cho việc trao đổi nghiệp vụ có thể bị sai sót.
Nhưng nếu bạn dùng mô hình khái niệm mà Chen đề xuất, đó lại là một câu chuyện khác.
Ưu điểm của Chen Notation (công cụ dùng để xây dựng lên mô hình ER của Chen) là dễ hiểu ngay cả với người dùng nghiệp vụ thuần túy. Nếu bạn dành ra khoảng 30 phút để tìm hiểu về các ký hiệu này, bạn sẽ hiểu được các nghiệp vụ sau trong mô hình ví dụ trên:
- Thực thể EMPLOYEE có nhiều thuộc tính khác nhau, trong đó có key Ssn, có thuộc tính dạng tổ hợp (composite attribute) Name,...
- Thực thể EMPLOYEE này có mối quan hệ phân cấp (hirerachical relation) với chính nó thông qua cơ chế "giám sát - supervision": Một người có thể giám sát nhiều người.
- Mọi nhân viên - EMPLOYEE đều phải làm việc trong một DEPARTMENT và mọi DEPARTMENT phải có EMPLOYEE làm việc trong đó.
- Mỗi EMPLOYEE có thể quản lý một và chỉ một DEPARTMENT, mỗi DEPARTMENT đều phải được quản lý bởi duy nhất một EMPLOYEE.
- Bạn có thể hiểu được thêm những nghiệp vụ nữa trong đó...
Chúng ta sẽ bàn luận chi tiết về cách mô hình hóa khái niệm một bài toán trong những bài viết khác.
Chuẩn hóa dữ liệu
Như đã đề cập bên trên, mô hình khái niệm được chuyển sang giai đoạn mô hình hóa logic mà sau đó kết quả sẽ là một mô hình logic.
Trong giai đoạn này, mục đích chính là:
- Chuyển các thực thể và liên kết trong mô hình ER trở thành các bảng logic hai chiều mà Codd định nghĩa.
- Chuẩn hóa mô hình để giảm dữ liệu dư thừa cũng như chuẩn hóa lại logic nghiệp vụ.
Cách chuyển ER sang Logical Model chúng ta sẽ bàn bạc trong những bài viết khác, chúng sẽ có quy tắc và các lựa chọn. Ở đây ta bàn sâu hơn vào việc chuẩn hóa dữ liệu.
(Ở phạm vi bài viết này, "chuẩn hóa dữ liệu" nghĩa là "chuẩn hóa cơ sở dữ liệu quan hệ").
Normalization
Định nghĩa (chặt chẽ): Chuẩn hóa dữ liệu là phương pháp:
Thay thế R bởi tập các phép chiếu R1, …, Rn sao cho ít nhất một trong R1, …, Rn ở dạng chuẩn hóa cao hơn R và sao cho
Với mọi giá trị r có thể của R, nếu các giá trị tương ứng r1, …, rn của R1, …, Rn join lại cùng nhau tạo ra kết quả bằng với r.
Định nghĩa khác (dễ hiểu hơn):
Chuẩn hóa cơ sở dữ liệu là quá trình cấu trúc một cơ sở dữ liệu quan hệ theo một loạt các hình thức chuẩn hóa nhằm giảm thiểu sự dư thừa dữ liệu và cải thiện tính toàn vẹn của dữ liệu.
Chuẩn hóa chia làm nhiều cấp độ khác nhau (từ thấp tới cao):
- 1NF: Đảm bảo mỗi thuộc tính trong một dòng dữ liệu chỉ chứa một giá trị duy nhất.
- 2NF: Đảm bảo rằng không có một thuộc tính nào ngoài key phụ thuộc vào một tập nhỏ trong key.
- 3NF: Đảm bảo rằng không có thuộc tính nào ngoài key lại phụ thuộc vào một thuộc tính ngoài key khác.
- BCNF: Đảm bảo rằng không có thuộc tính trong key nào lại phụ thuộc vào một thuộc tính ngoài key.
- 4NF: Đảm bảo rằng các thuộc tính độc lập với nhau không được thuộc về cùng một relation.
- 5NF: Đảm bảo rằng việc tách một relation ở các lần từ thứ 3 trở đi vẫn đảm bảo không mất mát thông tin.
Thường thì ta chỉ xem xét chuẩn hóa dữ liệu tới BCNF nhưng trong một số trường hợp ta cần phải đạt được 4NF và 5NF. Hai chuẩn cuối này dựa trên căn cứ rất khác so với bốn chuẩn đầu tiên, là những chuẩn dựa vào Functional Dependency - Phụ thuộc hàm.
Định nghĩa cụ thể và phân tích chi tiết hơn về từng cấp chuẩn hóa sẽ ở các bài viết khác.
Mục đích chính của chuẩn hóa
Chuẩn hóa dữ liệu nhằm hai mục đích chính
1. Sửa một thiết kế không chính xác về mặt logic, và
2. Giảm thiểu dư thừa dữ liệu trong một thiết kế đúng đắn về logic.
Chi tiết tại đây https://softwaredesign.vn/hai-muc-dich-chinh-cua-chuan-hoa-normal-forms
Khi bàn về chuẩn hóa, ta cũng nên đề cập tới phi chuẩn - denormalization.
Denormalization
Denormalization hay "phi chuẩn" thực sự là gì không có định nghĩa chính thức. Điều này xuất phát từ chính hành vi mà nó thực hiện: không có quy tắc cụ thể. Do đó, thường thì người ta sẽ định nghĩa phi chuẩn dựa vào chính chuẩn hóa:
Phi chuẩn là ngược lại với chuẩn hóa, còn chuẩn hóa được định nghĩa rõ ràng.
Khác với quá trình chuẩn hóa - là quá trình dựa trên các quy tắc toán học rõ ràng và ta biết được khi nào cần dừng lại, phi chuẩn khó cho ta biết được ta nên dừng ở đâu. Điều này hoàn toàn dựa vào cảm tính, tình huống, và do đó, không được quy định rõ ràng.
Phi chuẩn thường vì lý do "hiệu năng". Tôi cần lưu thừa dữ liệu này vì dữ liệu này cần truy vấn nhanh chóng đáp ứng nhu cầu người dùng. Nếu tôi chuẩn hóa, nghĩa là dữ liệu này nằm ở bảng khách, tôi sẽ cần join các bảng này lại với nhau, ảnh hưởng rất lớn đến hiệu năng.
Đó là điều mà chúng ta thường nghe, thường nghĩ và rất hay thực hiện. Nhưng, đó không phải là động lực đúng nghĩa của phi chuẩn.
Phi chuẩn gây ra nhiều vấn đề hơn là lợi ích nó mang lại:
- Gây ra các vấn đề bất thường khi cập nhật dữ liệu (ở các thao tác insert, update, delete) do dư thừa dữ liệu.
- Gây ra sai logic nghiệp vụ.
- Và, chính yếu tố dư thừa dữ liệu gây ra dư thừa dữ liệu.
Chúng ta sẽ bàn về phi chuẩn ở những bài viết sau nhưng ở đây chúng ta sẽ chốt lại rằng:
Chỉ coi phi chuẩn là lựa chọn cuối cùng khi mà ta không còn cách nào khác có thể nâng cao hiệu năng ứng dụng. Bởi vì một khi đã quyết định phi chuẩn là ta đã quyết định đi trên một con đường rất dễ trơn trượt.