

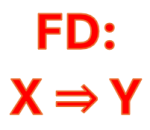
Lý thuyết của F. Codd về RD rất đơn giản, dựa vào hai trụ cột chính: Lý thuyết tập hợp và lý thuyết về đại số quan hệ. Ở đó, ông cho rằng:
- Dữ liệu nằm trong một bảng (relation) hai chiều với các dòng (tuples) và các cột (attributes).
- Các tuple không có thứ tự và có tính duy nhất (không có hai tuple nào trùng nhau).

Các hàng và cột giao nhau tại một điểm ta gọi là cell. Cell data chứa thông tin về dữ liệu mà ta muốn lưu trữ, gọi là fact.
Rất đơn giản, 1NF yêu cầu:
Cell data cần đảm bảo tính atomic.
Nghĩa là mỗi một giá trị của một thuộc tính của bất kỳ dòng dữ liệu nào cũng chỉ chứa duy nhất một giá trị. Cùng làm rõ vấn đề này.
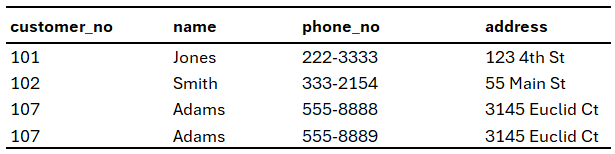
Giả sử, ta có một relation chứa 3 thuộc tính: name, phone_no, và address như sau:

Relation trên có thuộc tính phone_no vi phạm tính atomic ở dòng thứ 3 do chứa nhiều hơn một giá trị: "555-8888, 555-8889". phone_no được gọi là thuộc tính đa trị - multivalued attribute.
Để tiện theo dõi, ta sẽ ký hiệu relation trên như sau: R(A, { B }, C). Với { B } thể hiện thuộc tính đa trị.
Tại sao ta gặp thuộc tính đa trị?
Thuộc tính đa trị không mang lại quá nhiều lợi ích cho ta. Có thể có một số tình huống sau khiến ta gặp dữ liệu như vậy:
- Giao diện ứng dụng cung cấp textfield cho người dùng nhập thông tin đặc thù, ví dụ số điện thoại, tên trường đã học, tên các loại chứng chỉ đã có nhưng
- Ứng dụng không có logic validate định dạng dữ liệu, hoặc
- Đây là những thông tin mang tính chất bổ sung, không cần validate.
- Thông tin không có nhu cầu quản lý. Ví dụ, không cần quản lý xem người dùng có bao nhiêu số điện thoại, tốt nghiệp những trường học nào,...
- Một số nơi còn sử dụng nested-data: Một dòng dữ liệu master có một thuộc tính chứa toàn bộ list danh sách dữ liệu slave trong đó.
Vấn đề của thuộc tính đa trị
Thiết kế dữ liệu có thuộc tính đa trị thường mang lại vấn đề hơn là lợi ích.
Sẽ thế nào nếu đội phát triển nhận được yêu cầu thống kê số lượng số điện thoại mã mỗi khách hàng đang có, quản lý cập nhật từng số điện thoại riêng,...?
Một số trường hợp tinh vi hơn khi ứng dụng của bạn cho phép nhiều user có thể cùng được cập nhật một thông tin (ví dụ nhiều quản trị viên cùng thao tác trên một user khách hàng):
- Quản trị viên 1 cập nhật số điện thoại thứ nhất và cập nhật dữ liệu thành "555-8877, 555-8889", đồng thời lúc đó
- Quản trị viên 2 cập nhật thành "555-8888, 555-8899".
Lúc này, nếu không có cơ chế kiểm soát Concurrency Control, ta rất dễ bị sai sót thông tin: Quản trị viên 1 tưởng rằng mình đã cập nhật thành công nhưng thực ra dữ liệu đó đã bị ghi đè bởi quản trị viên 2. Khi bạn càng tổ hợp dữ liệu lại thành một thuộc tính duy nhất thì khi quản lý nó, bạn càng gặp rủi ro về xung đột.
Do đó, việc tách thông tin riêng biệt cho thuộc tính, tức đảm bảo tính atomic cho nó, là một yêu cầu cấp thiết.
Chuẩn hóa
Chuẩn hóa dữ liệu để lên 1NF là rất dễ dàng. Ta có hai công thức:
- R(A, { B }, C) => R(A, B, C).
- R(A, { B }, C) => R1(A, C) và R2(A, B).
Cách 1. R(A, { B }, C) => R(A, B, C)
Đây là cách thuần túy phân tách value của thuộc tính đa trị, đưa mỗi value đơn đó vào từng row được nhân bản lên từ row ban đầu. Kết quả như hình sau:
Cách này mang một số đặc điểm sau:
- Không cần tạo thêm bảng mới, giúp data model giữ nguyên được cấu trúc ban đầu.
- Nhưng vấn đề ta thấy dễ dàng: trùng lặp dữ liệu giữa các dòng mới được phân tách, chỉ khác nhau ở giá trị đơn trị được bóc tách ra. Và sau này bạn sẽ thấy, cặp thuộc tính sẽ hợp lại thành một concatenate key của bảng này, và khi đó, bảng này vi phạm chuẩn 2NF và sẽ khiến chúng ta bắt buộc thực hiện kỹ thuật "decomposition - phân rã" để đưa bảng về dạng chuẩn hóa cao hơn. Đây là hướng đi mà "cách 2" dưới đây muốn tránh.
Cách 2. R(A, { B }, C) => R1(A, C) và R2(A, B)
Sử dụng phân rã, có kết quả như sau:

Nhận xét:
- Từ một bảng ban đầu, giờ đây ta cần quản lý hai bảng. Do đó, mô hình nói chung là phức tạp hơn.
- Ưu điểm hơn cách 1 vì tránh được dư thừa dữ liệu. Sau này bạn sẽ thấy, việc phân rã này đã giúp cho ví dụ của ta không chỉ đạt được 1NF mà còn đạt được 2NF - là điều mà cách 1 không làm được.
Định nghĩa 1NF
Relation R có các thuộc tính A₁, … , Aₙ thuộc các kiểu dữ liệu T₁, … , Tₙ tương ứng.
R ở dạng 1NF khi và chỉ khi với mọi tuple t trong R, giá trị Aⱼ trong t thuộc kiểu Tⱼ (j = 1, 2, …, n).
Bạn có thể thấy định nghĩa này không hề giới hạn kiểu của từng thuộc tính. Thường thì ta sẽ sử dụng những kiểu có cấu trúc đơn giản như number, varchar,... nhưng ta hoàn toàn có thể khai báo một dạng cấu trúc dữ liệu phức tạp hơn và đặt vào đó một giá trị đơn trị.
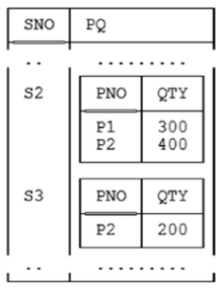
Bảng trên vi phạm 1NF do tại dòng SNO = "S2", thuộc tính PQ chứa hai giá trị của kiểu mà nó thuộc về.
Hiểu lầm
Ta thường gặp một lầm tưởng về bảng 1NF: Một bảng đạt chuẩn 1NF có nghĩa là nó sẽ có primary key (PK)...
Xem lại định nghĩa ta thấy rằng 1NF không yêu cầu bảng phải có PK. Điều này có nghĩa là: Bảng có thể tuân thủ 1NF mà không cần có một PK được chỉ định.
Và ngược lại, một bảng chỉ đơn thuần có PK cũng không đảm bảo rằng nó tuân thủ 1NF. Xem lại ví dụ ở hình 2 ta thấy "name" có thể đảm nhận PK (ta nói "có thể" vì đây chỉ là dữ liệu mẫu) và thuộc tính "phone_no" vẫn không phải là atomic. Do đó, bảng này không đạt chuẩn 1NF.
Overloading a Column
Đã khi nào bạn đã thiết kế hoặc gặp một thiết kế mà ở đó một thuộc tính mang nhiều ý nghĩa nghiệp vụ khác nhau? Ví dụ

Trong hình 5, một bảng có 3 thuộc tính: ID, NAME, và STATUS. Trong đó, người thiết kế tận dụng STATUS để lưu thông tin hai nghiệp vụ khác nhau: ghi lại trạng thái xử lý của bản ghi và lưu lại mã lỗi nếu xuất hiện. Việc này tuy giúp mô hình mang tính dùng lại cao, tiết kiệm không gian lưu trữ nhưng lại gây khó khăn cho quá trình tìm hiểu nghiệp vụ, phân tích, khai thác sau này.
Đây là hiện tượng "quá tải thuộc tính" trong thiết kế dữ liệu.
Bài viết liên quan: